mirror of
https://github.com/gmemstr/blog.gabrielsimmer.com.git
synced 2024-09-16 18:41:11 +01:00
Initial commit.
Still some work to do, but basic content is here.
This commit is contained in:
commit
c8ed961e17
2
.circleci/config.yml
Normal file
2
.circleci/config.yml
Normal file
|
|
@ -0,0 +1,2 @@
|
|||
# Todo
|
||||
version: 2.1
|
||||
3
.gitignore
vendored
Normal file
3
.gitignore
vendored
Normal file
|
|
@ -0,0 +1,3 @@
|
|||
content/posts/exported
|
||||
content/posts/drafts
|
||||
public
|
||||
6
archetypes/default.md
Normal file
6
archetypes/default.md
Normal file
|
|
@ -0,0 +1,6 @@
|
|||
---
|
||||
title: "{{ replace .Name "-" " " | title }}"
|
||||
date: {{ .Date }}
|
||||
draft: true
|
||||
---
|
||||
|
||||
5
config.toml
Normal file
5
config.toml
Normal file
|
|
@ -0,0 +1,5 @@
|
|||
baseURL = "https://blog.gabrielsimmer.com/"
|
||||
languageCode = "en-us"
|
||||
title = "Gabriel's Blog"
|
||||
theme = "gs"
|
||||
ignorefiles = [ "content/posts/exported/.*", "content/posts/drafts/.*" ]
|
||||
52
content/posts/30-04-2016.md
Normal file
52
content/posts/30-04-2016.md
Normal file
|
|
@ -0,0 +1,52 @@
|
|||
---
|
||||
title: 30/04/2016
|
||||
date: 2016-04-30
|
||||
---
|
||||
|
||||
#### DD/MM/YYYY -- a monthly check-in
|
||||
|
||||
A lot has happened this month. From NodeMC v5 and v6 to
|
||||
a new website redesign to a plethora of new project ideas, May is going
|
||||
to be a much busier month, so I think I should check-in.
|
||||
|
||||
NodeMC, one of my most beloved projects thus far, has been going far
|
||||
better than I could have ever imagined, with more than 30 unique cloners
|
||||
in the past 30 days and about 300 unique visitors, those have far
|
||||
outpaced my other projects. And to top it, off, 13 lovely stars. Version
|
||||
1.5.0 (aka v5) [recently launched with plugin
|
||||
support](https://nodemc.space/blog/3), and has been a monumental release for me in terms of
|
||||
what it has taught me and what the contributors and I have achieved. A
|
||||
big hats-off to [md678685](https://twitter.com/md678685) for helping with the plugin system and other fixes
|
||||
within in the release. NodeMC v6, however, is going to be even bigger.
|
||||
[Jared Allard](https://jaredallard.me/) of nexe fame (among other projects) has taken
|
||||
interest in the project and has rewritten the bulk of it using ES6
|
||||
standards, which both md678685 and I have been learning, and has
|
||||
recently decided to rewrite the stock dashboard using the React
|
||||
framework. I could not be happier working with him on v6.
|
||||
|
||||
On a smaller note, [my personal website](http://gabrielsimmer.com)
|
||||
has had a bit of a facelift. I decided to do so after months of using a
|
||||
free HTML5 template that really did not offer a whole lot of room to
|
||||
customize. My new site allows me to add pretty much an unlimited number
|
||||
of projects and other information as I see fit. It's built using my
|
||||
favorite CSS framework [Skeleton](http://getskeleton.com/),
|
||||
which I will forever see as superior to Bootstrap, despite not being
|
||||
updated in more than a year (I may have some free time to fork it), and
|
||||
using a nice font called [Elusive Icons](http://elusiveicons.com/) for
|
||||
the small icons. I'm throwing the source up on GitHub as I type this
|
||||
post ([it's up!](https://github.com/gmemstr/GabrielSimmer.com)).
|
||||
|
||||
I have a lot of projects in my head. Too many to count or even write
|
||||
down. It's going to be a crazy few months as some of my more long-term
|
||||
projects (some of them mine, others I'm just working on) are realized
|
||||
and launched. I really don't want to say much, but I know that several
|
||||
online communities, namely the Minecraft and GitHub communities, will be
|
||||
very excited when I am able to talk more freely on what I have coming
|
||||
up.
|
||||
|
||||
_*Okay, maybe I'll tease one thing -- I recently bought the YourCI.space domain, which I am not just partking!*_
|
||||
|
||||
Just a quick heads up as well, everyone should go check out [Software Engineering Daily](http://softwareengineeringdaily.com/). I am going to be on the show later next month, but I recommend you subscribe to that wonderful podcast regardless. I will be sure to link the specific episode when it comes out over on [my Twitter](https://twitter.com/gmemstr)
|
||||
|
||||
> "If you have good thoughts they will shine out of your face like
|
||||
> sunbeams and you will always look lovely." -- Roald Dahl
|
||||
0
content/posts/_index.md
Normal file
0
content/posts/_index.md
Normal file
36
content/posts/a-bit-about-batch.md
Normal file
36
content/posts/a-bit-about-batch.md
Normal file
|
|
@ -0,0 +1,36 @@
|
|||
---
|
||||
title: A bit about batch
|
||||
date: 2016-01-21
|
||||
---
|
||||
|
||||
#### Or: why there is no NodeMC installer
|
||||
|
||||
Can we just agree on something -- Batch scripting is
|
||||
terrible and should go die in a fiery pit where all the other Windows
|
||||
software goes? I don't think I can name any useful features of batch
|
||||
scripting besides text-based (and frankly pointless) DOS-like games. It
|
||||
sucks.
|
||||
|
||||
I recently tried to port the NodeMC install script from Linux (bash) to
|
||||
Windows (batch), and while it seemed possible, the simple tasks of
|
||||
downloading a file, unzipping it, and moving some others around, it
|
||||
proved to be utterly impossible.
|
||||
|
||||
_A quick note before I proceed -- Yes, I realize something like a custom built installer in a more traditional language would have been possible, however I wanted to see what I could do without it. Also I'm lazy._
|
||||
|
||||
First and foremost, there is no native way to download files properly.
|
||||
Most Linux distros ship with cURL or wget (or are installed fairly early
|
||||
on), which are both great options for downloading and saving files from
|
||||
the internet. On Windows, it is suggested
|
||||
[BITS](https://en.wikipedia.org/wiki/Background_Intelligent_Transfer_Service) could do the job. However, on execution, it simply
|
||||
*does not work*. I got complaints from Windows about how it didn't want
|
||||
to do the thing. *Fine*. Let's move on to the other infuriating thing.
|
||||
|
||||
Stock Windows has the ability to unzip files just file. So why the hell
|
||||
can I not call that from batch? There is no reason I shouldn't be able
|
||||
to. But alas, it cannot be done, [at least not
|
||||
easily](https://stackoverflow.com/questions/21704041/creating-batch-script-to-unzip-a-file-without-additional-zip-tools) \*grumble grumble\*
|
||||
|
||||
In conclusion: Batch is useless. It should be eradicated and replaced
|
||||
with something useful. Because as of now it has very little if any
|
||||
redeeming qualities that make me want to use it.
|
||||
33
content/posts/a-post-a-day.md
Normal file
33
content/posts/a-post-a-day.md
Normal file
|
|
@ -0,0 +1,33 @@
|
|||
---
|
||||
title: A Post A Day...
|
||||
date: 2015-10-28
|
||||
---
|
||||
|
||||
#### Keeps the psychiatrist away.
|
||||
|
||||
I'm trying to keep up with my streak of a post every day on Medium,
|
||||
mostly because I've found it really fun to write. I think Wednesdays
|
||||
will become a sort of 'weekly check-in', going over what I have done and
|
||||
what there is yet to do.
|
||||
|
||||
So, what have I accomplished this week?
|
||||
|
||||
- Created a link shortner.
|
||||
- Made the staff page for Creator Studios.
|
||||
- Started updating [my homepage](http://gabrielsimmer.com)
|
||||
- Fixed an issue with Moat-JS (pushing out soon).
|
||||
- Removed mc.gabrielsimmer.com and all the deprecated projects.
|
||||
- Moved to Atom for development.
|
||||
|
||||
And what do I hope to accomplish?
|
||||
|
||||
- Fix my link shortner.
|
||||
- Work on the video submission page for Creator Studios.
|
||||
- Whatever else needs doing.
|
||||
- Complete my week-long streak of Medium posts.
|
||||
|
||||
It's hard to list what I want to accomplish because things just come up
|
||||
that I have no control over. But nonetheless, I will report back next
|
||||
Wednesday.
|
||||
|
||||
Happy coding!
|
||||
29
content/posts/ajax-is-cool.md
Normal file
29
content/posts/ajax-is-cool.md
Normal file
|
|
@ -0,0 +1,29 @@
|
|||
---
|
||||
title: AJAX Is Cool
|
||||
date: 2015-11-07
|
||||
---
|
||||
|
||||
#### Loading content has never been smoother
|
||||
|
||||
I started web development (proper web development anyways) using pretty much only PHP and HTML -- I didn't touch JavaScript at all, and CSS was usually handled by Bootstrap. I always thought I was doing it wrong, but I usually concluded the same thing every time.
|
||||
|
||||
> "JavaScript is too complex. I'll stick with PHP."
|
||||
|
||||
Only recently have I been getting into JavaScript, and surprisingly have
|
||||
been enjoying it. I've been using mainly AJAX and jQuery for GET/POST
|
||||
requests for loading and displaying content, which I do realize is *just
|
||||
barely* scratching the surface of what it can do, but it's super useful
|
||||
because I can do things such as displaying a loading animation while it
|
||||
fetches the data or provide nearly on-the-fly updating of a page's
|
||||
content (I am working on updating ServMineUp to incorporate AJAX for
|
||||
this reason). I'm absolutely loving my time with it, and I hope I'll be
|
||||
able to post more little snippets of code like I did for
|
||||
[HoverZoom.js](/posts/hoverzoom-js). Meanwhile, I encourage everyone to try their hand at AJAX & JavaScript. It's powerful and amazing.
|
||||
|
||||
#### Useful Resources
|
||||
|
||||
[jQuery API](http://api.jquery.com/)
|
||||
|
||||
[JavaScript on Codecademy](https://www.codecademy.com/learn/javascript)
|
||||
|
||||
[JavaScript docs on MDN](https://developer.mozilla.org/en-US/docs/Web/JavaScript)
|
||||
39
content/posts/an-api-a-day.md
Normal file
39
content/posts/an-api-a-day.md
Normal file
|
|
@ -0,0 +1,39 @@
|
|||
---
|
||||
title: An API A Day
|
||||
date: 2016-07-11
|
||||
---
|
||||
|
||||
#### Keeps... other productivity away?
|
||||
|
||||
[Update: GitHub org is available here with more info & rules.](https://github.com/apiaday)
|
||||
|
||||
I've been in a bit of a slump lately, NodeMC hasn't
|
||||
been as inspiring and development has been a bit slow, other projects
|
||||
are on hold as I wait for third parties, so I haven't really been
|
||||
working on much development wise.
|
||||
|
||||
#### So I can up with a challenge: **An API A Day**.
|
||||
|
||||
The premise is simple -- Every day, I pick a new API to build an
|
||||
application with from [this list](https://www.reddit.com/r/webdev/comments/3wrswc/what_are_some_fun_apis_to_play_with/) (from reddit). From the time I start I have the rest
|
||||
of the day to build a fully-functional prototype, bugs allowed but core
|
||||
functionality must be there. And it can't just be a "display all the
|
||||
data" type app, it has to be interactive in some form.
|
||||
|
||||
An example of this is [Artdio](http://gmem.pw/artdio), which was the inspiration for this challenge. I
|
||||
built the page in about 3 hours using SoundCloud's JavaScript API
|
||||
wrapper, just as a little "how does this work" sort of challenge.
|
||||
|
||||
So how is this going to be organised?
|
||||
|
||||
I'm going to create a GitHub organization that will house the different
|
||||
challenges as separate repositories. To contribute, all you'll need to
|
||||
do is fork the specific day / API, copy your project into it's own
|
||||
folder (named YOURPROJECTNAME-YOURUSERNAME), then create a pull request
|
||||
to the main repository. I don't know the specific order I personally
|
||||
will be going through these APIs, so chances are I will bulk-create
|
||||
repositories so you can jump around at your own pace, or you can request
|
||||
a specific repository be created.
|
||||
|
||||
If you have any questions or need something cleared up, feel free to
|
||||
[tweet at me :)](https://twitter.com/gmem_)
|
||||
120
content/posts/building-a-large-scale-server-monitor.md
Normal file
120
content/posts/building-a-large-scale-server-monitor.md
Normal file
|
|
@ -0,0 +1,120 @@
|
|||
---
|
||||
title: Building a Large-Scale Server Monitor
|
||||
date: 2017-01-24
|
||||
---
|
||||
|
||||
#### Some insight into the development of [Platypus](https://github.com/ggservers/platypus)
|
||||
|
||||
If you've been around for a while, you may be aware I
|
||||
work at [GGServers](https://ggservers.com) as a developer primarily focused on exploring new
|
||||
areas of technology and computing. My most recent project has been
|
||||
Platypus, a replacement to our very old status page
|
||||
([here](https://status.ggservers.com/), yes we know it's down). Essentially, I had three
|
||||
goals I needed to fulfil.
|
||||
|
||||
1. [Able to check whether a panel (what we refer to our servers as, for
|
||||
they host the Multicraft panel) within our large network is offline.
|
||||
This is by far the easiest part of the project, however
|
||||
implementation and accuracy was a problem.]
|
||||
2. [Be able to fetch server usage statistics from a custom script which
|
||||
can be displayed on a webpage so we can accurately monitor which
|
||||
servers are under or over utilised.]
|
||||
3. [Build a Slack bot to post updates of downed panels into our panel
|
||||
reporting channel.]
|
||||
|
||||
#### Some Rationale
|
||||
|
||||

|
||||
|
||||
*Why did you choose Python? Why not Node.js or even PHP (like our
|
||||
current status page)?* Well, I wanted to learn Python, because it's a
|
||||
language I never fully appreciated until I built tfbots.trade (which is
|
||||
broken, I know, I haven't gotten around to fixing it). At that point, I
|
||||
sort of fell in love with the language, the wonderful syntax and PEP8
|
||||
formatting. Regardless of whether I loved it or not, it is also a hugely
|
||||
important language in the world of development, so it's worth learning.
|
||||
|
||||
*Why do you use JSON for all the data?* I like JSON. It's easy to work
|
||||
with, with solid standards and is very human readable.
|
||||
|
||||
#### Tackling Panel Scanning
|
||||
|
||||
[Full video](https://youtu.be/xAXT1mOFccM)
|
||||
|
||||
Right so the most logical way to see if a panel is down is to make a
|
||||
request and see if it responds. So that's what I did. However there were
|
||||
a few gotchas along the way.
|
||||
|
||||
First, sometimes our panels aren't actually **down**, but just take a
|
||||
little bit to respond because of various things like CPU load, RAM
|
||||
usage, etc., so I needed to determine a timeout value so that scanning
|
||||
doesn't take too long (CloudFlare adds some latency between a client and
|
||||
the actual "can't reach server" message). Originally, I had this set to
|
||||
one second, thinking that even though my own internet isn't fast enough,
|
||||
the VPS I deployed it to should have a fast enough network to reach
|
||||
them. This turned out to not be true -- I eventually settled on 5
|
||||
seconds, which is ample time for most panels to respond.
|
||||
|
||||
Originally I believed that just fetching the first page of the panel (in
|
||||
our case, the login for Multicraft), would be effective enough.
|
||||
Unfortunately what I did not consider is all the legwork the panel
|
||||
itself has to do to render out that view (Multicraft is largely
|
||||
PHP-based). But fortunately, the request doesn't really care about the
|
||||
result it gets back (*yet*). So to make it easier, I told the script to
|
||||
get whatever is in the /platy/ route. This of course makes it easier for
|
||||
deployment of the stat scripts, but I'll get to those in a bit.
|
||||
|
||||
Caching the results of this scan is taken care of by my useful JSON
|
||||
caching Python module, which I haven't forked off because I don't feel
|
||||
it's very fleshed out. That said, I've used it in two of my handful of
|
||||
Python projects (tfbots and Platypus) and it has come in very handy
|
||||
([here's a gist of it](https://gist.github.com/gmemstr/78d7525b1397c35b7db6cfa858f766c0)). It handles writing and reading cache data with no
|
||||
outside modules aside from those shipped with Python.
|
||||
|
||||
#### Stat Scripts
|
||||
|
||||
An integral part of a status page within a Minecraft hosting company is
|
||||
being able to see the usage stats from our panels. I wrote two scripts
|
||||
to help with this, one in Python and one in PHP, which both return the
|
||||
same data. It wasn't completely necessary to write two versions, but I
|
||||
was not sure which one would be favoured for deployment, and I figured
|
||||
PHP was a safe bet because already we have PHP installed on our panels.
|
||||
The Python script was a backup, or if others wanted to use Platypus but
|
||||
without the kerfuffle of PHP.
|
||||
|
||||
The script(s) monitor three important usage statistics; CPU, RAM and
|
||||
disk space. It returns this info as a JSON array, with no extra frills.
|
||||
The Python script implements a minimal HTTP server to handle requests as
|
||||
well, and only relies on the psutil module for getting stats.
|
||||
|
||||

|
||||
|
||||
#### Perry the Platypus
|
||||
|
||||
Aka the Slack bot, which we have affectionately nicknamed. This was the
|
||||
most simple part of the project to implement thanks to the
|
||||
straightforward library Slack has for Python. Every hour, he/she/it
|
||||
(gender undecided, let's not force gender roles people! /s) posts to our
|
||||
panel report channel with a list of the downed panels. This is the part
|
||||
most subject to change as well, because after a while it feel a lot like
|
||||
a very annoying poke in the face every hour.
|
||||
|
||||
#### →Going Forward →
|
||||
|
||||
I am to continue to work on Platypus for a while; I am currently
|
||||
implementing multiprocessing so that when it scans for downed panels,
|
||||
the web server can still respond. I am having some funky issues with
|
||||
that though, namely the fact Flask seems to be blocking the execution of
|
||||
functions once it is started. I'm sure there's a fix, I just haven't
|
||||
found it yet. I also want to make the frontend more functional -- I am
|
||||
definitely implementing refreshing stats with as little JavaScript as
|
||||
possible, and maybe making it slightly more compact and readable. As for
|
||||
the backend, I feel like it's pretty much where it needs to be, although
|
||||
it could be a touch faster.
|
||||
|
||||
Refactoring the code is also on my to do list, but that is for much,
|
||||
much farther down the line.
|
||||
|
||||
I also need an adorable logo for the project.
|
||||
|
||||

|
||||
57
content/posts/diy-api-documentation.md
Normal file
57
content/posts/diy-api-documentation.md
Normal file
|
|
@ -0,0 +1,57 @@
|
|||
---
|
||||
title: DIY API Documentation
|
||||
date: 2016-02-24
|
||||
---
|
||||
|
||||
#### How difficult can writing my own API doc pages be?
|
||||
|
||||
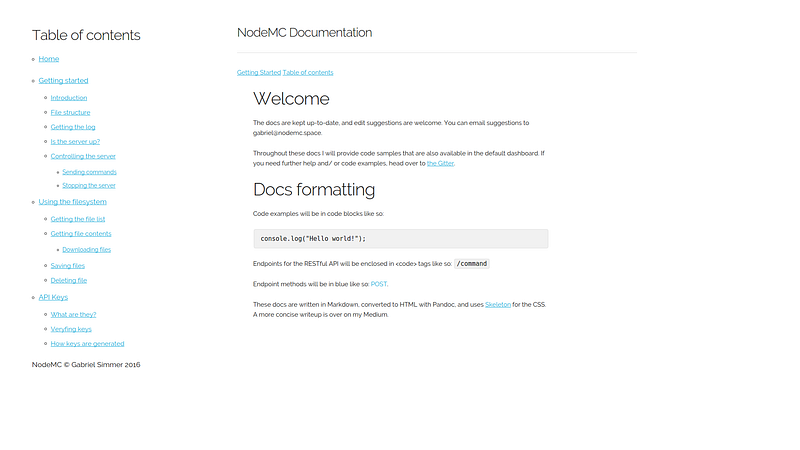
I needed a good documentation solution for
|
||||
[NodeMC](https://nodemc.space)'s
|
||||
RESTful API. But alas, I could find no solutions that really met my
|
||||
particular need. Most API documentation services I could find were
|
||||
either aimed more towards web APIs, like Facebook's or the various API's
|
||||
from Microsoft, very, very slow, or just far too expensive for what I
|
||||
wanted to do (I'm looking at you,
|
||||
[readme.io](http://readme.io)). So,
|
||||
as I usually do, I decided to tackle this issue myself.
|
||||
|
||||
|
||||
|
||||
I knew I wanted to use Markdown for writing the docs, so the first step
|
||||
was to find a Markdown-to-HTML converter that I could easily automate
|
||||
for a smoother workflow. After a bit of research, I came along
|
||||
[Pandoc](http://pandoc.org/), a
|
||||
converter that does pretty much everything I need, including adding in
|
||||
CSS resources to the exported file. Excellent. There is also quite a few
|
||||
integrations for several Markdown (or text) editors, but none for vsCode
|
||||
so I didn't need to worry about those, choosing instead to use the \*nix
|
||||
watch command to run my 'makefile' every second to build to HTML.
|
||||
|
||||
The next decision I had to make was what to use for CSS. I was very
|
||||
tempted to use Bootstrap, which I have always used for pretty much all
|
||||
of my projects that I needed a grid system for. However, instead, I
|
||||
decided on the much more lightweight
|
||||
[Skeleton](http://getskeleton.com/)
|
||||
framework, which does pretty much everything I need to in a much smaller
|
||||
package. Admittedly it's not as feature-packed as Bootstrap, but it does
|
||||
the job for something that is designed to be mostly text for developers
|
||||
who want to get around quickly. Plus, it's not too bad looking.
|
||||
|
||||
So the final piece of the puzzle was "how can I present the information
|
||||
attractively?", which took a little bit more time to figure out. I
|
||||
wanted to do something like what most traditional companies will do,
|
||||
with a sidebar table of contents, headers, etc. The easiest way to do
|
||||
this was a bit of custom HTML and a handy bit of Pandoc parameters, and
|
||||
off to the races.
|
||||
|
||||
Now at this point you're probably wondering why I'm not just using
|
||||
Jekyll, and the answer to that is... well, I just didn't. Honestly I
|
||||
wanted to try to roll my own Jekyll-esque tool, which while slightly
|
||||
less efficient still gets the job done.
|
||||
|
||||
So where can you see these docs in action? Well, you can view the
|
||||
finished result over at
|
||||
[docs.nodemc.space](http://docs.nodemc.space), and the source code for the docs (where you can make
|
||||
suggestions as pull requests) is available on [my
|
||||
GitHub](https://github.com/gmemstr/NodeMC-Docs), which I hope can be used by other people to build
|
||||
their own cool docs.
|
||||
38
content/posts/enjoying-my-time-with-nodejs.md
Normal file
38
content/posts/enjoying-my-time-with-nodejs.md
Normal file
|
|
@ -0,0 +1,38 @@
|
|||
---
|
||||
title: Enjoying my time with Node.js
|
||||
date: 2015-12-19
|
||||
---
|
||||
|
||||
#### Alternatively, I found a project to properly learn it
|
||||
|
||||
A bit of background -- I've been using primarily PHP for any backend
|
||||
that I've needed to do, which while works most certainly doesn't seem
|
||||
quite right. I have nothing against PHP, however it feels a bit dirty,
|
||||
almost like I'm cheating when using it. I didn't know any other way,
|
||||
though, so I stuck with it.
|
||||
|
||||
Well I recently found a project I could use to learn Node.js -- a
|
||||
Minecraft server control panel -- and I've actually been enjoying it,
|
||||
much more than I have PHP. Here's a demo of my project:
|
||||
|
||||
https://www.youtube.com/embed/c0IGKEmHyOM?feature=oembed
|
||||
|
||||
It's all served (very quickly) by a Node.js backend, that wraps around
|
||||
the Minecraft server and uses multiple POST and GET routes for various
|
||||
functions, such as saving files. The best part about it is how fast it
|
||||
is (obviously), but the second greatest thing is the efficiency. For
|
||||
example, in PHP, for me to implement some new thing, I'd most likely
|
||||
need to create a new file, fill in my variables and methods, and point
|
||||
my JavaScript (or AJAX) towards it. And I have no real good way of
|
||||
debugging it. However with Node.js, it's three lines of code (no
|
||||
seriously) to implement a new route with Express that will perform a
|
||||
function. Not only that, but it's *so easy to debug.* Because of how
|
||||
it's run, instead of just producing a 500 error page, it can actually
|
||||
log the error before shutting off the program, which is so much more
|
||||
useful then then old 'cat /var/log/apache2/error.log'.
|
||||
|
||||
My advice to anyone looking to get into web development is *learn
|
||||
Node.js.* Not only is it a new web technology that is only increasing in
|
||||
size, but it's powerful, open with about a billion extensions, and can
|
||||
help you learn more JavaScript, a big part of dynamic content on HTML5
|
||||
websites.
|
||||
16
content/posts/hello-world-again.md
Normal file
16
content/posts/hello-world-again.md
Normal file
|
|
@ -0,0 +1,16 @@
|
|||
---
|
||||
title: Hello, world! (Again)
|
||||
date: 2021-07-04
|
||||
---
|
||||
|
||||
Welcome back to the blog! Sort of.
|
||||
|
||||
After much thought, I've decided to move my blog off of Medium and back to a place I can fully control. It wasn't really a difficult decision; Medium as a platform has changed a fair amount since I began using it, just as I have. Rather than nuking the entirety of my previous posts, I exported and cleaned them up for archival (although I did seriously consider just starting fresh).
|
||||
|
||||
There are some things I should address about these posts. First, they are a product of their time. I don't say that to excuse racism (there is none in these old posts), but rather both my writing style and view of the world. These older posts span from 2015 to 2018, when I was between the ages of 15 and 18 (at the time of this post, I'm 21). I've done my best to clean up the posts after the Medium export, but content left as-is where possible. While I maintain an archive of the original export, I've decided against commiting the raw files and any drafts that my account contained (mostly because they're in very rough states and are mostly for personal nostalgia/reflection).
|
||||
|
||||
I will not be editing these older posts. However, posts from this one onwards are fair game!
|
||||
|
||||
On the technical side, this site is using [Hugo](https://gohugo.io) to generate static files. It seemed like the simplest option. Commits run through a CircleCI pipeline (I work there, and am most familiar with the platform, hence no GitHub Actions) and get pushed to a branch that GitHub Pages serves up. There are simpler approaches, but the important thing is that the content is in plaintext, rather than a platform's database, and can be moved to wherever is needed.
|
||||
|
||||
I'm unsure how regular posts will be to this blog, but there may be the odd post here and there - follow me on Twitter to be notified, or the [generated RSS feed](https://blog.gabrielsimmer.com/index.xml) - [@gmem_](twitter.com/gmem_).
|
||||
51
content/posts/hoverzoom-js.md
Normal file
51
content/posts/hoverzoom-js.md
Normal file
|
|
@ -0,0 +1,51 @@
|
|||
---
|
||||
title: HoverZoom.js
|
||||
date: 2015-11-05
|
||||
---
|
||||
|
||||
#### A quick script
|
||||
|
||||
I'm working on a new, super secret project, and as such I'm going to
|
||||
post bits and pieces of code that are generic enough but could be
|
||||
useful.
|
||||
|
||||
This particular one will zoom in when you hover over an image, and only
|
||||
requires jQuery to work. Enjoy!
|
||||
|
||||
```javascript
|
||||
/*
|
||||
HoverZoom.js by Gabriel Simmer
|
||||
|
||||
Provides zoom-in on hover over element,
|
||||
requires jQuery :)
|
||||
|
||||
Obviously you can change "img" to whatever
|
||||
you'd like, e.g ".image" or "#image"
|
||||
*/
|
||||
var imgHeight=720;
|
||||
var imgWidth=1280; // Naturally you should replace these with your own values
|
||||
|
||||
$( document ).on({
|
||||
mouseenter:function() {
|
||||
$("img").animate({
|
||||
"height": imgHeight,
|
||||
"width": imgWidth
|
||||
});
|
||||
},
|
||||
mouseleave:function(){
|
||||
$("img").animate({
|
||||
"height": "100%",
|
||||
"width": "100%"
|
||||
})
|
||||
}}, "img");
|
||||
|
||||
```
|
||||
|
||||
Of course, be sure to include the following at the bottom of your *body*
|
||||
element:
|
||||
|
||||
```html
|
||||
<script src="https://ajax.googleapis.com/ajax/libs/jquery/1.11.3/jquery.min.js></script>
|
||||
<! -- HoverZoom JS -->
|
||||
<script src="js/hoverzoom.js"></script>
|
||||
```
|
||||
|
|
@ -0,0 +1,52 @@
|
|||
---
|
||||
title: I discovered a /r/programmingcirclejerk of NodeMC...
|
||||
date: 2016-03-02
|
||||
---
|
||||
|
||||
#### Haters do exist, but hey, publicity right?!
|
||||
|
||||
So recently I was looking at the graphs for NodeMC's
|
||||
traffic on GitHub and realized... there was a thread from
|
||||
/r/programmingcirclejerk (which I won't link for obvious reasons) that
|
||||
was directing a bit of traffic (actually quite a bit) to the GitHub
|
||||
repository. So out of idle curiosity of just having woken up, I decided
|
||||
*"Why not?"* and opened up the thread. I was greeted with what on the
|
||||
surface seemed like hatred towards me and my product but upon further
|
||||
investigation I found it seemed more general mockery towards a few of my
|
||||
decisions or wording -- or just Node.js in general. So let's analyze
|
||||
and reply to some comments!
|
||||
|
||||

|
||||
|
||||
So this is obviously attacking my wording in the README... I claim that
|
||||
because NodeMC is written in Node.js, it is fast. And I admit, maybe
|
||||
Node.js in general is not that fast. *However* -- NodeMC has actually
|
||||
proven to be quite speedy in tests, so I stand by my statement, perhaps
|
||||
with some tweaked wording...
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
This is most likely touching on (or slapping) my little confusion about
|
||||
\*nix permissions. The EPIPE error was due to the fact Java couldn't
|
||||
access the Minecraft server jarfiles, and was throwing an error that
|
||||
Node.js just had no f\*kng clue what to do with it. I did manage to fix
|
||||
it.
|
||||
|
||||

|
||||
|
||||
Unfortunately, I do have to agree with this commenter, Node.js isn't
|
||||
exactly the most reliable thing, and **most definitely** not the easiest
|
||||
to debug \*grumble EPIPE grumble\*. Now that said, it's not as
|
||||
unreliable as Windows 10 \*badum tish\*.
|
||||
|
||||

|
||||
|
||||
And the final comment. I do want to learn Ruby at some point. But I did
|
||||
laugh when I saw this lovely comment.
|
||||
|
||||

|
||||
|
||||
And of course, my comment, to finish off the pile of steaming comments.
|
||||
I love you all\~
|
||||
43
content/posts/im-using-notepadpp.md
Normal file
43
content/posts/im-using-notepadpp.md
Normal file
|
|
@ -0,0 +1,43 @@
|
|||
---
|
||||
title: I'm Using Notepad++
|
||||
date: 2015-10-27
|
||||
---
|
||||
|
||||
#### Again
|
||||
|
||||
UPDATE! I've started using Atom (thanks to Oliver Dunk for reminding me
|
||||
about it), enjoy it a ton with the remote-edit package. I'll have a
|
||||
follow-up post with more thoughts :P
|
||||
|
||||
Maybe I'm just crazy. Or maybe there are some things I just really need
|
||||
my development area to do. Because of my job as CTO of a YouTube
|
||||
Network, I need to do a lot of work on the website, which means I need
|
||||
real-time access to it. I have a locally hosted server using XAMPP, but
|
||||
it's not enough -- for example, when I have subdirectories, or
|
||||
a .htaccess rule, I have to do this
|
||||
|
||||
```
|
||||
<link href="/projectname/css/bootstrap.min.css" rel="stylesheet">
|
||||
```
|
||||
|
||||
which is obviously incorrect when deploying it to a real server.
|
||||
|
||||
Maybe I should explain a bit more -- for the past few months, I've been
|
||||
sticking with Visual Studio Code, Microsoft's entry into the text-editor-that-also-has-syntax-highlighting-and-other-IDE-stuff area
|
||||
(or as I sometimes call it, simple IDEs). It's not bad, but for things
|
||||
like plugin support, it simply isn't there.
|
||||
|
||||
So why Notepad++? A piece of software that looks like it's from the 80s?
|
||||
|
||||
Well, for one, NppFTP. A small plugin that allows me to edit and upload
|
||||
file in basically real-time on a server. I've been using it for about 20
|
||||
minutes and it's already *super* useful. Second, oodles of
|
||||
customization. I'm just getting back into it, but I already like it (the
|
||||
top bar is still ugly though).
|
||||
|
||||

|
||||
|
||||
As soon as vsCode adds FTP support, I'll probably immediately switch
|
||||
back to it. I love the aesthetic, and the autocomplete is *decent*. But
|
||||
for the time being, I'm sticking with Notepad++.
|
||||
37
content/posts/improving-old-sites.md
Normal file
37
content/posts/improving-old-sites.md
Normal file
|
|
@ -0,0 +1,37 @@
|
|||
---
|
||||
title: Improving Old Sites
|
||||
date: 2015-10-30
|
||||
---
|
||||
|
||||
#### The magical 15%
|
||||
|
||||
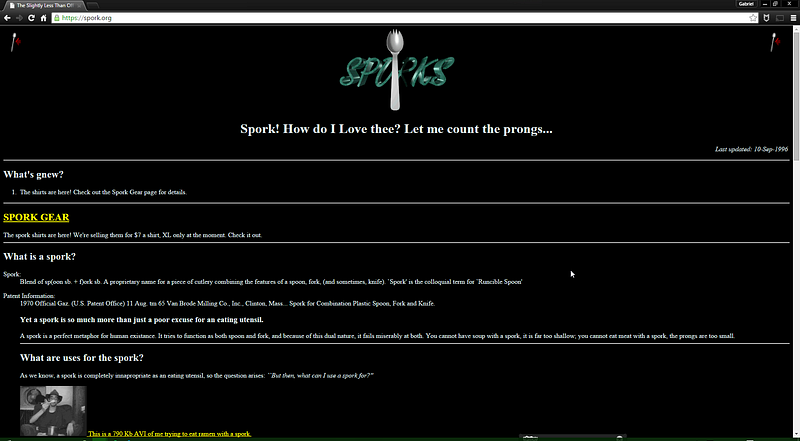
Because of the nature of my schooling (mostly online), I'm provided with
|
||||
a lot of very old, often dead, links. But, when a link does work, I'm
|
||||
often greeted with a hideous site.
|
||||
|
||||
|
||||
|
||||
(This wasn't for a school thing by the way).
|
||||
|
||||
How do you improve such a thing! Well, first is my magical "padding by
|
||||
percent". Open up the "Inspect Element" tool and let's get to work.
|
||||
|
||||

|
||||
|
||||
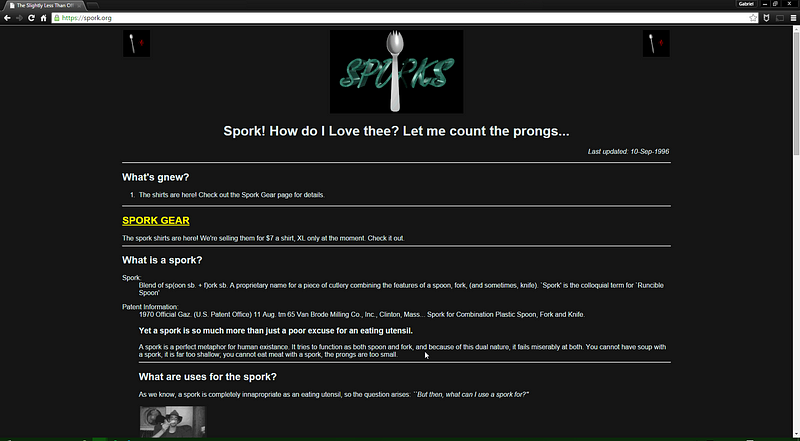
I tend to go for a padding of about 15%. It's usually a pretty
|
||||
comfortable place to be. But... that background... and that font...
|
||||
let's tweak that. Just a bit.
|
||||
|
||||
|
||||
|
||||
A few simple steps goes a long way to improve the ability to use and
|
||||
read a site.
|
||||
|
||||

|
||||
|
||||
Obviously, this is a lot of work for just one little site. But hopefully
|
||||
soon I'll be able to get my own custom Chrome plugin working for this,
|
||||
because it's one of my biggest issues with using the web.
|
||||
|
||||
And for my next post, I'll talk about the benefits of learning how to
|
||||
use a .htaccess file!
|
||||
44
content/posts/its-wrong-to-compare-tech-companies.md
Normal file
44
content/posts/its-wrong-to-compare-tech-companies.md
Normal file
|
|
@ -0,0 +1,44 @@
|
|||
---
|
||||
title: It's Wrong to Compare Tech Companies
|
||||
date: 2015-10-23
|
||||
---
|
||||
|
||||
|
||||
Alright, everyone calm down, it's not always true but read on to see my
|
||||
reasoning.
|
||||
|
||||
Recently I was talking to my friend and fellow web developer [Sam
|
||||
Bunting](http://sambunting.biz/). We set on to the topic of Google being evil after me asking why he chose a Windows Phone over something like an Android phone or an iPhone. His reasoning was simply that
|
||||
|
||||
> Because in all honesty, I like Microsoft and dislike Google, The
|
||||
> phones for a fairly powerful spec is quite cheap compared to things
|
||||
> like iPhones, I really like flat design and personalisation of my
|
||||
> stuff (Which I can do really easily on Windows Phones) and it is fast,
|
||||
> not just out of the box, but *\[after a lot of use\]* it appears to
|
||||
> have not lost any performance at all.
|
||||
|
||||
He pointed out that he feels google is an 'evil company', and that they get everything they -- and what they don't get they bully out of
|
||||
existence. We went on to compare Google vs. Microsoft (a friendly
|
||||
sparring match if you will) and I left with the conclusion that we
|
||||
really should not be comparing those two companies -- just like how we shouldn't compare apple to oranges.
|
||||
|
||||
Tech companies try to innovate (at least, most of them). They find new
|
||||
ways to do things and earn some revenue off that. They do things the way
|
||||
they want to. The way they see is the 'right way'. It's not really fair
|
||||
to compare Android to Windows Phone because they're aiming for two
|
||||
different things. Android is going for customizability and aiming for
|
||||
all markets, whereas Windows Phone seems to be aiming more for the
|
||||
low-to-medium end business-oriented smartphones for people who want to
|
||||
get stuff done and don't care about changing their launcher or flashing
|
||||
custom ROMs. It's like that for iOS too. iOS is more focused on Apple's
|
||||
closed garden, and people who invest in their (rather pricey compared to
|
||||
the competition) technology want to be enclosed in Apple's walled garden
|
||||
of safety, where maybe the ability to change their icons isn't there but
|
||||
the safety and speed (although with iOS 9 that's debatable) are present.
|
||||
|
||||
Obviously, some companies could be easy to compare, like Intel and AMD,
|
||||
or Nvidia and AMD, but that's because they're in the same sort of
|
||||
business -- they make processors and graphics cards for PCs, among
|
||||
other endeavours. But for the most part I don't think it's fair to
|
||||
compare Microsoft vs. Google vs. Apple. They're all going their own
|
||||
directions.
|
||||
54
content/posts/lets-clear-up-some-things-about-ggservers.md
Normal file
54
content/posts/lets-clear-up-some-things-about-ggservers.md
Normal file
|
|
@ -0,0 +1,54 @@
|
|||
---
|
||||
title: Let's clear up some things about GGServer
|
||||
date: 2017-03-15
|
||||
---
|
||||
|
||||
#### We get a lot of hate directed to us because we aren't as transparent. Let's fix that.
|
||||
|
||||
I've been a developer at GGServers for about a year
|
||||
now. In that time I've gotten a good sense of how things work behind the
|
||||
scenes at the budget Minecraft server host. I've (this is going to sound
|
||||
canned but it's genuine) dedicated myself to improving the state of the
|
||||
technology running everything. I've had to put up with hate and abuse
|
||||
from unhappy customers, some justified others not so much. One thing
|
||||
that some people have pointed out is how opaque commununications from us
|
||||
can be -- hell, in the four years we've had our Twitter we've tweeted
|
||||
less than 1,000 times (250 tweets/year on average).
|
||||
|
||||
Let's make something clear -- We are still a very small company. Like,
|
||||
*really* small. We have five dedicated support staff, answering tickets
|
||||
of various technical depth. These people unfortunately are not
|
||||
"full-time". They don't come in to an office 9am-5pm, answer your
|
||||
tickets and go home. They're spread out. When we say 24/7 support, we
|
||||
don't mean your ticket will be taken care of immediately, we mean that
|
||||
our support system doesn't go down. We -- I -- Get it, you want your
|
||||
question answered right away, and properly. We've gotten a lot better at
|
||||
replying to things quickly, and typically manage to get the entire
|
||||
ticket queue handled every week or so.
|
||||
|
||||
Let's talk about server downtime. It sucks. You can't access your
|
||||
servers, can't pull your files to move to another host. Currently, we
|
||||
have on person in our limited staff who has access to our hosting
|
||||
provider, and he is busy very often. Our previous systems administrator
|
||||
just sort of went AWOL, leaving us a bit stuck in terms of responding to
|
||||
server downtime. I was just recently granted the title of sysadmin, and
|
||||
am still waiting on our provider to grant me access to our hardware. And
|
||||
to be clear this does not mean I get a keycard to datacenters where I
|
||||
can walk to a rack of servers, pull ours out and tinker. It means I have
|
||||
as-close-to-hardware-as-possible remote access, where I can troubleshoot
|
||||
servers as if I was using a monitor plugged into it, but I never
|
||||
physically touch the bare metal. *But* it does mean I can get servers up
|
||||
and running properly. Once our provider allows me access. Hopefully that
|
||||
clears that up a bit.
|
||||
|
||||
We try to limit our interactions outside of tickets for two reasons.
|
||||
One, we can log everything that is filed in our system. Two, and most
|
||||
importantly, we're not quite sure what we can and cannot say. There's a
|
||||
fine line between being transparent and divulging company secrets. I
|
||||
feel comfortable saying what I am because I don't feel anyone could gain
|
||||
a competitive advantage knowing these facts. I would love to get access
|
||||
to the Twitter account and start using it to our advantage but it's
|
||||
going to take a while.
|
||||
|
||||
Anyways, if you guys have any more questions or comments, keep it civil
|
||||
and I will do my best to answer.
|
||||
51
content/posts/lets-talk-about-the-windows-taskbar.md
Normal file
51
content/posts/lets-talk-about-the-windows-taskbar.md
Normal file
|
|
@ -0,0 +1,51 @@
|
|||
---
|
||||
title: Let's talk about the Windows Taskbar
|
||||
date: 2015-11-21
|
||||
---
|
||||
|
||||
#### Or a small rant about why I hate the Windows (10) UI
|
||||
|
||||
Windows (insert version here) doesn't look good. I believe this is a very well established fact. OSX? That is a good interface. GNOME 3? It's okay. XFCE? Pretty sharp. So why can't Microsoft learn from them?
|
||||
|
||||
First off, Microsoft is stubborn. I've learned this very recently. They
|
||||
haven't changed much of their UI design over the years, haven't really
|
||||
rethought it. It's annoying, to say the least. Sure, they moved to
|
||||
making sharper edges (pun intended). And sure, they trying their tiled
|
||||
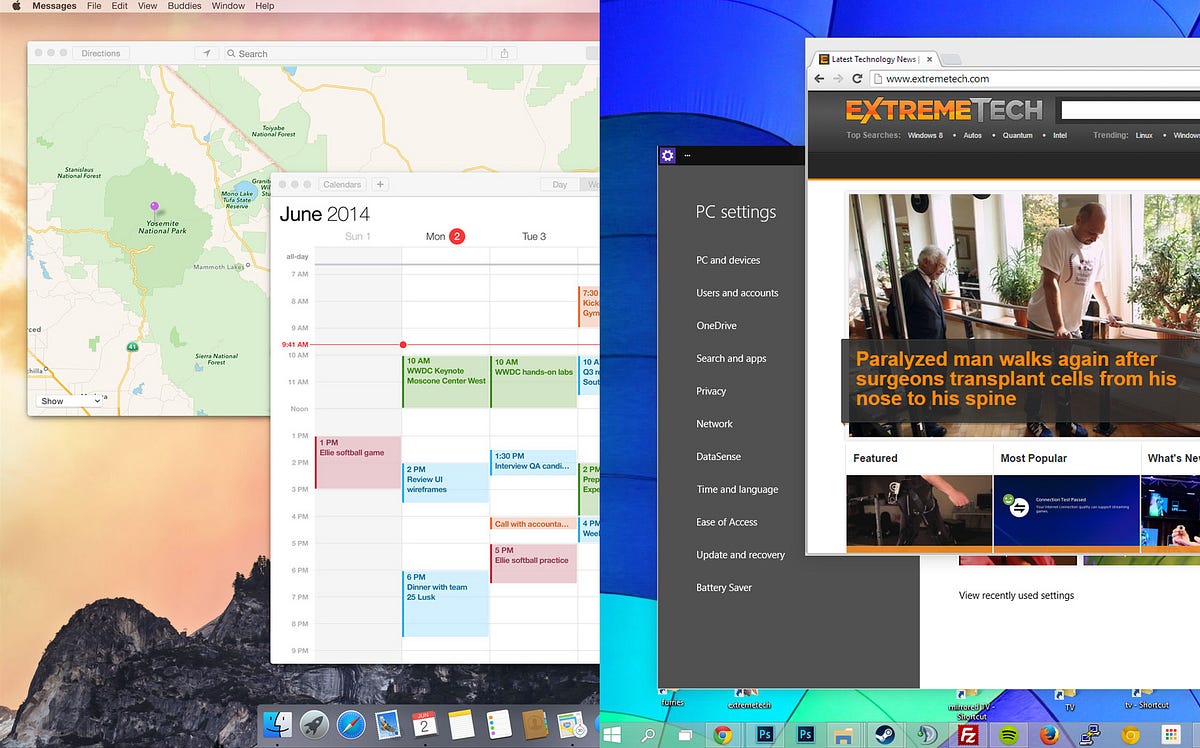
displays. But it's all garbage, compared to something like OSX's
|
||||
fantastic UI.
|
||||
|
||||
|
||||
|
||||
As you can see, OSX is *clean*. It's *soft.* It doesn't clutter up the
|
||||
taskbar the way Windows does, it doesn't have massive top bars on
|
||||
applications. The UI isn't fragmented between Metro (or Modern,
|
||||
whatever) and the programs of old. It's all cohesive.
|
||||
|
||||
Your obvious response to this may be something along the lines of *"Well
|
||||
Windows is open! We can change it!"*. But the thing is, *I don't want to
|
||||
change the OSX interface.* I freely admit, I am a bit of a sucker for
|
||||
design, and Apple usually takes the cake with their interfaces (despite
|
||||
being crap for customization, looking at you iOS).
|
||||
|
||||
My biggest problem is the Windows taskbar. I know, it's not something
|
||||
some people usually harp on, but I'm going to do it. First of all, it's
|
||||
too big. Notice how on OSX (I will use OSX as an example here) the bar
|
||||
is not only a lot shorter, *it grows only as needed.* Second, the
|
||||
Windows 10 taskbar just feels like it *wants* to be cluttered up,
|
||||
because there's so much space, whereas on OSX, it's short and simple.
|
||||
Nicely laid out and organized.
|
||||
|
||||
Let's take a look at my desktop for a second.
|
||||
|
||||

|
||||
|
||||
It flows. It works. It's simple. Everything I need is in that little
|
||||
rainmeter dock (more info on my entire desktop [here](https://www.reddit.com/r/desktops/comments/3tha11/had_some_inspiration_minimal_once_again/)), the clock is out of the way, and I can focus on work. The Windows taskbar is hidden at the top, made the smallest size possible, so that it stays out of the way (and at the top to mimic my favorite desktop environment XFCE). I don't want it taking up the real estate on my screen, and when a notification comes in (which is fairly often), I don't want to see it blinking in the taskbar. *I know I've
|
||||
received a message, and I will check it when I want.*
|
||||
|
||||
To summarize, Microsoft has to learn about good design. They need to
|
||||
pull a 1080. I kind of liked their flatter, sharper interface, but now I
|
||||
like my minimal, no frills or gimmicks setup.
|
||||
|
||||
At some point all this will be nullified because I'll be on Xubuntu or
|
||||
some other XFCE distro, but for now these are my feelings.
|
||||
90
content/posts/ltx-2017.md
Normal file
90
content/posts/ltx-2017.md
Normal file
|
|
@ -0,0 +1,90 @@
|
|||
---
|
||||
title: LTX 2017
|
||||
date: 2017-07-30
|
||||
---
|
||||
|
||||
#### The first Linus Tech Tips tech conival
|
||||
|
||||

|
||||
|
||||
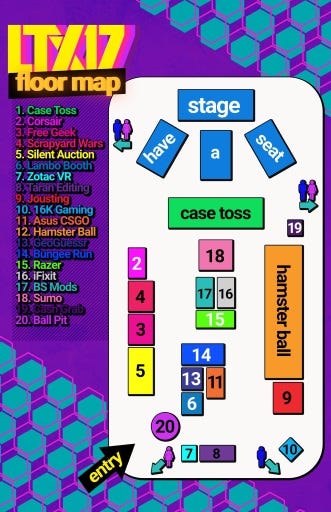
Anticipation was high as we approached the Langley
|
||||
Convention Center by bus, as my girlfriend and I eagerly awaited meeting
|
||||
one of our role models Linus Sebastian, and the crew of personalities
|
||||
that helped script, film, edit and perfect the seven videos a week Linus
|
||||
Media Group create, not including their secondary channels.
|
||||
|
||||
|
||||
|
||||
We were off to a good start -- all of our transit was on time, we
|
||||
spotted one of their newer hires on the bus there, and everyone was very
|
||||
friendly (I made the mistake of thinking that the event started at 10AM,
|
||||
it actually began at 11). I had a slight nagging in the back of my head
|
||||
however. The day before, the Linus Tech Tips account had tweeted out the
|
||||
map of the floor, and revealed the fact it was going to take place in an
|
||||
ice hockey rink (sans ice, unfortunately). That itself is not a bad
|
||||
thing -- hockey rinks are decently sized for such an event. However
|
||||
upon having our tickets scanned and claiming our ticket tier swag, we
|
||||
entered into the absolutely packed arena. And when I say packed, I mean
|
||||
*very* packed -- Becky and I had a hard time getting from one end to
|
||||
another.
|
||||
|
||||
The two primary causes that I could see include the fact that there were
|
||||
a ridiculous number of people there for the area, and the positioning of
|
||||
booths. The main attractions were positioned right by the door, which
|
||||
included the virtual reality booth, Razer, and 16K gaming. The floor
|
||||
also included a case toss (unfortunately not very well shielded), some
|
||||
carnival-esque inflatable games, some hardware maker booths, some other
|
||||
miscellaneous booths, and the main stage (we'll get to the stage in a
|
||||
minute). In fairness, the booths were all pretty spot on for the kind of
|
||||
audience Linus attracts, and the choices were very well done. The case
|
||||
toss had a major issue, however -- it was cordoned off with just ropes,
|
||||
with metal railings at the end to prevent too much destruction. Many
|
||||
cases ended up outside the area when thrown, whether slipping underneath
|
||||
the ropes or going over the top. Paranoia was high on my part on the
|
||||
topic of getting hit.
|
||||
|
||||

|
||||
|
||||
The highlight of the event was meeting Linus himself, face to face.
|
||||
Throughout the event whenever his feet touched the floor a circle of
|
||||
fans would appear around him, and if he moved you'd better watch out the
|
||||
for line of people behind him. However he handled it very well, and so
|
||||
did the cluster of fans -- nobody was pushy or overly aggressive, and
|
||||
he took his time with each person. We asked if he could sign both my
|
||||
girlfriend\'s laptop with the dbrand dragon skin (which he liked so much
|
||||
on the laptop he wanted to have it) and a hat, which he happily did. We
|
||||
also nabbed a selfie, which was awesome of him.
|
||||
|
||||

|
||||
|
||||
Unfortunately because of the seemingly lack of volunteers, most of the
|
||||
LMG (Linus Media Group) employees were running the marquee booths. This
|
||||
meant that they had less time to roam the show floor and meet fans, and
|
||||
while I appreciate the enthusiasm they had for their specific booth, it
|
||||
would have been nice to be able to say hi to more of them. I managed to
|
||||
meet Colton, Linus, Luke and Yvonne, and those meetings were somewhat
|
||||
spontaneous. The other members of the team were usually busy, either
|
||||
filming or helping run booths (or in the case of the sales team, making
|
||||
sure reveals went as they should have).
|
||||
|
||||
In a lighter note, the stage shows were great. There were some audio
|
||||
issues, and they did acknowledge them. The energy level was great, and
|
||||
the performances were great, with the unboxing of the Razer toasters,
|
||||
AMD Vega graphics card and a whole computer powered by AMD Threadripper
|
||||
and Vega. It was a bit unfortunate there was no barrier at the edge of
|
||||
the stage, which resulted in a lot of crowding as people tried to get
|
||||
closer for the best view (this was probably advantageous when Linus
|
||||
dropped a 4K Razer Blade laptop though). The raffle was a bit lackluster
|
||||
on our end as we didn't win anything, but the winners who did came away
|
||||
with an absolutely amazing set of prizes, ranging from headphones to a
|
||||
Titan Xp.
|
||||
|
||||
By the end of the day, we were both exhausted. We had a bit of a bad
|
||||
taste in our mouths as our expectations had been higher, or at the very
|
||||
least different. I wouldn't say disappointed -- that isn't the right
|
||||
word. It was a mix of eagerness for the next year and longing to work at
|
||||
LMG and help plan (or just work). We're both glad we went to the first
|
||||
one, so we could get a taste of what the next year could be like and
|
||||
also so we could say we were there.
|
||||
|
||||

|
||||
77
content/posts/making-a-link-shortner.md
Normal file
77
content/posts/making-a-link-shortner.md
Normal file
|
|
@ -0,0 +1,77 @@
|
|||
---
|
||||
title: Making a link shortner
|
||||
date: 2015-10-26
|
||||
---
|
||||
|
||||
My first thought when I got the following message
|
||||
|
||||
> Also, do you know how to make a URL shortner?
|
||||
|
||||
was *yes, probably, all things considered*. The last two days I'm been
|
||||
working on it, and it's turned out semi-well. There's a bug or two that
|
||||
needs fixing, but I figured I could post a short tutorial on how to do a
|
||||
simple one.
|
||||
|
||||
Right, I'm assuming a few things:
|
||||
|
||||
- [You have a web server]{#6644}
|
||||
- [You have a short domain/subdomain]{#0b99}
|
||||
- [You have MySQL & PhpMyAdmin]{#f238}
|
||||
- [You know how to use PHP]{#91de}
|
||||
|
||||
With that out of the way, let's set up our MySQL database. You'll need a
|
||||
table called **links**, in which it should have the columns laid out
|
||||
like so:
|
||||
|
||||
```yaml
|
||||
links:
|
||||
- actual [text]
|
||||
- short [text] (no other special values are required)
|
||||
```
|
||||
|
||||
Now, in our file named shorten.php (which you should download
|
||||
[here](https://ghostbin.com/paste/xk7gh), we need to edit a few things, first, make sure you change the PDO to connect to your database. Also, change
|
||||
|
||||
```php
|
||||
$b = generate_random_letters(5);
|
||||
```
|
||||
|
||||
to be any length you'd like. Lastly, make sure
|
||||
|
||||
```php
|
||||
value="url.com
|
||||
```
|
||||
|
||||
is the domain or subdomain of your site.
|
||||
|
||||
Great! Now that we can create short links, we need to interpret them. In
|
||||
long.php ([link](https://ghostbin.com/paste/yzbdj)), change the first
|
||||
|
||||
```php
|
||||
header('Location: url.com');
|
||||
```
|
||||
|
||||
to redirect to your main website. This will redirect users to the main
|
||||
website if there is no short link.
|
||||
|
||||
Fantastic, you're all done! As a bonus though, you can use a .htaccess
|
||||
file to tidy up your URL.
|
||||
|
||||
```
|
||||
RewriteEngine On
|
||||
RewriteCond %{REQUEST_FILENAME} !-f
|
||||
RewriteRule ^([A-Za-z0-9-]+)/?$ long.php?short=$1 [NC,L]
|
||||
```
|
||||
|
||||
So instead of *http://url.com/long.php?short=efkea*, it will be
|
||||
[*http://url.com/efkea*](http://url.com/efkea).
|
||||
|
||||
That's all for today :)
|
||||
|
||||
#### Files index:
|
||||
|
||||
[shorten.php -- GhostBin](https://ghostbin.com/paste/xk7gh)
|
||||
|
||||
[long.php -- GhostBin](https://ghostbin.com/paste/yzbdj)
|
||||
|
||||
[.htaccess -- GhostBin](https://ghostbin.com/paste/vznww)
|
||||
39
content/posts/moat-mobile.md
Normal file
39
content/posts/moat-mobile.md
Normal file
|
|
@ -0,0 +1,39 @@
|
|||
---
|
||||
title: Moat Mobile
|
||||
date: 2015-11-11
|
||||
---
|
||||
|
||||
## Or "The evolution of my web skills"
|
||||
|
||||

|
||||
|
||||
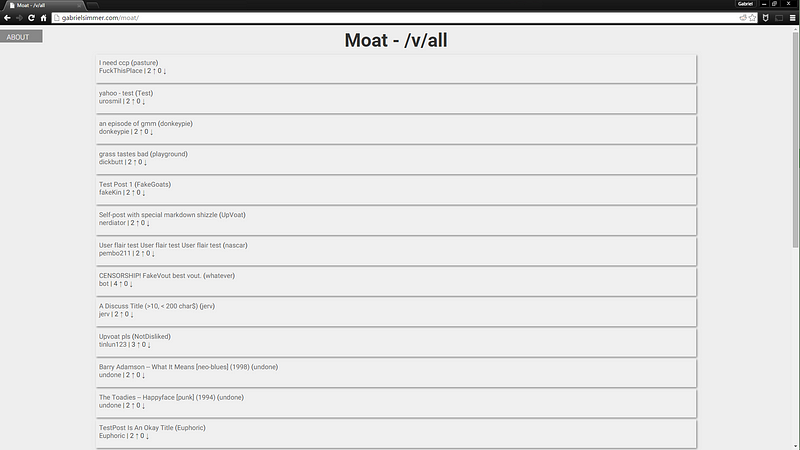
Moat, for the uninitiated (so, most of you), is my original project to
|
||||
learn how to use APIs. The API I chose was for [Voat.co](http://voat.co), a reddit competit- sorry, news aggregator that looks an awful lot like another
|
||||
website.
|
||||
|
||||
It started off pretty rough -- in fact, you can go preview it [here (dead link)](http://gabrielsimmer.com/moat/)
|
||||
|
||||
|
||||
|
||||
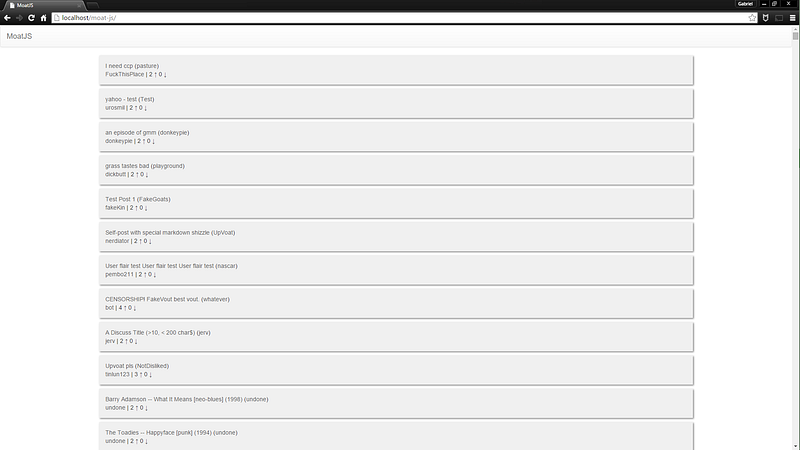
It... worked, but the UI wasn't really where I wanted it. I was also
|
||||
using the Voat alpha API, which was really slow. I looked ahead, and
|
||||
started working on a version that utilized JavaScript and AJAX, so I
|
||||
could display some sort of loading animation. I also used Bootstrap for
|
||||
it, so that I could scale it better on mobile.
|
||||
|
||||
|
||||
|
||||
The logical next step was to upgrade the interface, since so far it has
|
||||
been terrible. Again, I wanted to use Bootstrap, and I wanted to make it
|
||||
as mobile friendly as possible. And what's the best way of doing that?
|
||||
By using a [material design bootstrap
|
||||
theme](http://fezvrasta.github.io/bootstrap-material-design/). I also used [Material Floating Buttons](http://nobitagit.github.io/material-floating-button/)to give it navigation that made sense. I also made JavaScript do all the formatting work, using the .get() function in jQuery, and using my own server as an API middleman because of AJAX's lack of trust when getting info from other sites (for understandable reasons, but [here is how you can bypass it](https://ghostbin.com/paste/kf3pf)). And here is the final product.
|
||||
|
||||

|
||||
|
||||
The FAB requires a bit of tweaking, and I have a bit of functionality to
|
||||
add, but this is the product so far. I doubt I'll touch the styling for
|
||||
quite a while, unless it's to make the UI more material design like.
|
||||
|
||||
You can fork the project on the [GitHub
|
||||
page](https://github.com/gmemstr/moat-mobile) if you so please, and be sure to read the FAQ if you want to know what you can help out with.
|
||||
105
content/posts/moving-away-from-google.md
Normal file
105
content/posts/moving-away-from-google.md
Normal file
|
|
@ -0,0 +1,105 @@
|
|||
---
|
||||
title: Moving Away From Google
|
||||
date: 2017-11-23
|
||||
---
|
||||
|
||||
#### I'm starting to move outside the comfort bubble
|
||||
|
||||
If you've kept up with me on Twitter, you'll know what
|
||||
a huge fan of Google I am -- I have a Google Pixel XL (1st generation),
|
||||
a Google Wifi mesh network, a Google Home, and rely on Google services
|
||||
for a huge amount of work I do, including Google Drive/Docs, Gmail,
|
||||
Maps, Keep, and up until yesterday, Play Music.
|
||||
|
||||
But I'm starting to get tired of Google's products for a very simple and
|
||||
maybe even petty reason. *Their design is the least consistent thing
|
||||
ever.* I get it, Google is a huge company with tons of teams working on
|
||||
different things, but I find it hard to keep using their services when
|
||||
the interface for products is just straight up terrible compared to
|
||||
competition. Recently I switched away from using Google Play Music in
|
||||
favour of Spotify, which I had previously been using, and like the
|
||||
interface a lot more, as it's very consistent and not the garish orange
|
||||
of GPM. Despite being material design, the interface feels clunky and
|
||||
ugly compared to the refinement of Spotify, most likely in part due to
|
||||
work on the iOS app. Plus, it has a pretty great desktop app (albeit an
|
||||
Electron app, but I digress). All of the Drive apps (Docs, Sheets,
|
||||
Slides, etc) have a very clean and well designed look, but switching to
|
||||
the web version of Gmail is jarring, and the mobile app is simplistic at
|
||||
best -- it get's the job done at the very least. Not to mention I've
|
||||
found refreshing very slow compared to my own mail server I run for [Git
|
||||
Galaxy](https://gitgalaxy.com), which
|
||||
feels odd because logically Gmail should be faster, if not on par,
|
||||
considering Google's massive architecture. Hangouts is a beautifully
|
||||
designed experience, but it's become a very obvious second class citizen
|
||||
of Google's arsenal, thanks in part to Duo and Allo (we'll get to second
|
||||
class citizens in Google's world in a minute). It also does not support
|
||||
Firefox at all, even the latest beta version 58 (which is my daily
|
||||
driver), which requires me to keep Google Chrome installed -- clever
|
||||
move.
|
||||
|
||||
Let's switch gears away from UI/UX experience and talk about apps that
|
||||
Google seems to have forgotten or lost interest in. While I am aware
|
||||
some of these apps may have an active development team, they don't seem
|
||||
to be priority for Google as a whole, and this can lead to frustrations,
|
||||
such as the example above -- Hangouts does not support Firefox, even
|
||||
the beta 58 I currently run. I recognize Firefox Quantum just recently
|
||||
launched, but they had betas and nightlies available leading up to the
|
||||
release, so I don't believe there is any excuse for Hangout to not work
|
||||
outside of Chrome (I have not tested Edge). Also on topic of messaging
|
||||
apps from Google, they also offer Duo and Allo, two apps that
|
||||
essentially split the functionality of Hangouts in two. While some of
|
||||
the Android community was very vocal about this, and a large number of
|
||||
Hangouts users worried they were going to have to move, these feelings
|
||||
seem to have pettered out, although it does still seem possible for
|
||||
Google to pull the plug and force everyone over to their new offerings.
|
||||
The feeling of being second rate extends to Gmail as well, at least to a
|
||||
certain extent. Google is in no rush no to shut down their email
|
||||
service, as it's very valuable for keeping consumers locked in to their
|
||||
ecosysem and also provides them with a metric ton of data that they can
|
||||
sift through and utilize for advertising, [although recently they've
|
||||
claimed they will no longer do this](http://www.wired.co.uk/article/google-reading-personal-emails-privacy). That said, we don't neccesarily know if Google is
|
||||
still reading our emails and doing something else with the data. Which
|
||||
leads nicely into the next topic.
|
||||
|
||||
Security and privacy is something Google values greately, but it seems
|
||||
it's moreso to gain the trust of the consumer than to keep their own
|
||||
noses out of your data. Let's face it, Google is an advertising company,
|
||||
and little else. Everything they do is to expose people to more
|
||||
advertisements and maximize engagement to attract more advertisers.
|
||||
Their reach is incredible, especially considering AdSense and Analytics.
|
||||
With these two platforms in their arsenal, they have an almost infinite
|
||||
reach across the internet, living and collecting data on millions of
|
||||
websites that implement these services. The recent "Adpocalypse" on
|
||||
YouTube seems to be a case of runaway algorithms attempting to optimize
|
||||
YouTube for advertisers, or at least that's what most theorize. And
|
||||
frankly, it's not neccesarily a bad thing, but consumers need to
|
||||
recognize that Google is watching, and doesn't neccesarily have the end
|
||||
user in mind when it comes to accomplishing their goals.
|
||||
|
||||
So in summary -- Why am I slowly moving away from Google?
|
||||
|
||||
Their apps are inconsistant, which is to be expected in such a huge
|
||||
company with so many teams working on different things. Projects that
|
||||
aren't the forefront of Google's priorities suffer heavily, especially
|
||||
in an age where "the web" is accelerating very quickly and design is
|
||||
being refined constantly. Also, Google is an advertising company, at
|
||||
their core. It's how they earn the majority of their revenue, and
|
||||
despite ad blockers, it will continue to be. This isn't a problem on
|
||||
it's own, and I actually used to embrace the feeling of contributing so
|
||||
much data to Google, but the honeymoon period has worn off now, and I
|
||||
feel like I should cut back -- after all, millions of other people are
|
||||
contributing just as much data, so Google won't notice if they suddenly
|
||||
loose one. I run Firefox Nightly on my phone instead of Chrome, and am
|
||||
actively looking for alternatives to many of their other services,
|
||||
notably Gmail and Google Docs.
|
||||
|
||||
> Google does a bit of everything okay, but sometimes it's better to pay
|
||||
> a bit for a much more specific service that does one thing incredibly
|
||||
> well.
|
||||
|
||||
The final nail in the coffin for Google Play Music, if you were
|
||||
wondering, was the fact that YouTube Red is not available in Canada yet,
|
||||
which infuriates me and requires the use of a VPN. This coupled with the
|
||||
fact Google Play Music has a fairly limited catalogue compared to
|
||||
Spotify makes it difficult to recommend. If you can get YouTube Red with
|
||||
it, however, the price is worth it.
|
||||
62
content/posts/my-2017-project.md
Normal file
62
content/posts/my-2017-project.md
Normal file
|
|
@ -0,0 +1,62 @@
|
|||
---
|
||||
title: My 2017 Project
|
||||
date: 2016-12-22
|
||||
---
|
||||
|
||||
#### This one... this one will be fun
|
||||
|
||||
As some of you may know, or not know, I am a developer
|
||||
at heart, writing and playing with code to my hearts content. However
|
||||
there are some other areas of technology I really, *really* want to play
|
||||
with. These last few months I've been toying with the idea of building
|
||||
my own homelab, teaching myself the basics of enterprise and small-scale
|
||||
networks (and then breaking them, of course). I've also wanted to look
|
||||
into server farms and whatnot, but that seems a bit too much considering
|
||||
my budget and space, among other things.
|
||||
|
||||
#### The Plan
|
||||
|
||||
First, I want to start with a really solid second hand network switch.
|
||||
The primary function of this is to allow me to extend my ethernet
|
||||
capabilities -- right now I'm essentially limited to one physical
|
||||
ethernet jack and have to rely on WiFi for everything else. This will
|
||||
allow me to have a permanent home for my Pi, laptop station, and
|
||||
whatever else I add to the network. Plus I think network switches look
|
||||
really cool.
|
||||
|
||||
Next, once I can afford it, I want to either build or buy a good
|
||||
rackmount NAS, along with an actual rack to mount it on (and add the
|
||||
switch to said rack). Ideally I'd want to have around 8TB of storage to
|
||||
play with initially, a few 2TB drives most likely with unRaid. I'd want
|
||||
a rack mount case that can support a fair few drives so later down the
|
||||
line I can add more and larger disks. Specs wise, I have no clue what a
|
||||
NAS would need, but I would assume nothing too high-end. If all else
|
||||
fails, I'd end up buying a second hand one off eBay and going from
|
||||
there. This will then connect to the switch -- whether I allow it to
|
||||
communicate with the outside world I can't say for sure yet (this is
|
||||
after all a rambly brainstorm kind of blog post). This NAS would be a
|
||||
"hot" server, one that is frequently read from, modified, written to,
|
||||
and so forth.
|
||||
|
||||
The second NAS box would be a highly-redundant backup system, limited to
|
||||
just the internal network and comprised of many tried-and-tested drives.
|
||||
This server would be upgraded and read from far less than the "hot" NAS,
|
||||
but needs to make up for lack of read speed in sheer bytes of data it
|
||||
can hold and keep intact even in cases like drive failure. This box
|
||||
would most likely be bought second hand, depending on the situation.
|
||||
Capacity I do not have concretely in my head, however I want to aim for
|
||||
about 30TB of raw storage (5x6TB drives, 10x3TB drives if the server is
|
||||
big enough).
|
||||
|
||||
The final system, the pièce de résistance if you will, is a high-end
|
||||
dedicated computation-heavy server. In my head (and heart) this would be
|
||||
equipped with two Intel Xeon cores, one or two GPUs (one gaming, one
|
||||
dedicated to crunching numbers like a Quadro), and a couple SSDs to keep
|
||||
it happy in terms of storage. This box would be the server that handles
|
||||
media encoding, 3D rendering (most likely renting it out later), serving
|
||||
up websites, and whatever the heck else I can get the power-hungry thing
|
||||
to do. Overkill, most likely, and probably end up selling some computing
|
||||
space in the form of VPSs and whatnot, but it would be a damn cool thing
|
||||
to have around (my power bill would never be happy).
|
||||
|
||||
Anywho, time to get cracking.
|
||||
79
content/posts/my-career.md
Normal file
79
content/posts/my-career.md
Normal file
|
|
@ -0,0 +1,79 @@
|
|||
---
|
||||
title: My Career
|
||||
date: 2015-10-23
|
||||
---
|
||||
|
||||
This is less of a resumé and more of a look back at some of the projects
|
||||
I've been involved in, most of which failed -- and *usually* not
|
||||
because of me.
|
||||
|
||||
I believe my first ever attempt to make a name for myself was as part of
|
||||
the long-defunct "NK Team".
|
||||
|
||||
> [I was involved pretty early on](https://twitter.com/TheNkTeam/status/201040884190543872)
|
||||
|
||||
|
||||
I joined on because of my "skills" (aka I knew how to do
|
||||
HTML -- barely) to develop the website. I also became their PR person,
|
||||
handling the Twitter account. It went okay, honestly. We were building a
|
||||
prison Minecraft server and actually had a fairly nice sized community
|
||||
built up. It fell apart when I left after realizing where things were
|
||||
headed, and that Andrew, the leader, was a complete and utter *dick*.
|
||||
|
||||
> [Last ever tweet from the account](https://twitter.com/TheNkTeam/status/217286027591688194)
|
||||
|
||||
I believe my second team I joined was Team Herobrine, a modding team my
|
||||
cousin was already a part of.
|
||||
|
||||
> [Tweet](https://twitter.com/TeamHerobrine/status/249592769541193728)
|
||||
|
||||
It was attempting to bring an Aether-level mod that featured
|
||||
"Herobrine's Realm". And looking back, it was doomed from the start. The
|
||||
lead was a kid probably around 11 (I honestly don't remember) who, while
|
||||
he did create an actual working mod that I tested myself, I am convinced
|
||||
he just took some sample code and threw it together. It really went
|
||||
nowhere, and eventually fell apart when the lead developer stopped
|
||||
showing up on Skype. Honestly, it was a cool project that did have
|
||||
potential.
|
||||
|
||||
I don't quite remember what order some of these projects/groups come in,
|
||||
but this was around the time Team Herobrine was dying off. My friends
|
||||
and I from high school decided we wanted to make our own Minecraft
|
||||
server, named Tactical Kingdom.
|
||||
|
||||
> [](https://twitter.com/TKingdoms/status/298607656774561792)
|
||||
|
||||
It actually got pretty far in -- we were pretty much ready to launch,
|
||||
but then our host disappeared in a puff of smoke, taking with it our
|
||||
hard work and money. I still haven't learned to do frequent backups of
|
||||
anything though. (You can go check out the crappy website courtesy of
|
||||
the WayBack Machine [here](https://web.archive.org/web/20130512015002/http://tacticalkingdoms.clanteam.com/)
|
||||
|
||||
I pause here to reflect and try to recall what else I did. I honestly
|
||||
can't remember. I did some solo projects, mostly bad maps nobody should
|
||||
play.
|
||||
|
||||
Later on, more recently, I applied to be a map builder for the infamous
|
||||
SwampMC server, where I met some wonderful people, on of which I now
|
||||
hold very close to my heart.
|
||||
|
||||
(Sadly, I can't find the first Tweet from when I joined.)
|
||||
|
||||
It was a cool community with some awesome people. But sometimes awesome
|
||||
people don't work well together, especially when people overlap in
|
||||
power. Power struggles caused the server, and the spinoff HydroMC (or
|
||||
HydroGamesMC depending who you ask) to disappear, the group of friends
|
||||
once dedicated to it now completely disintegrated. There is a bright
|
||||
side to it though. While working on it, I became the developer, and
|
||||
developed my coding ability, which has landed me as CTO of Creator
|
||||
Studios.
|
||||
|
||||
> [Tweet](https://twitter.com/CreatorStudios_/status/656958850176786432)
|
||||
|
||||
Which is utterly fantastic. I do enjoy developing things on my own, but
|
||||
I do like having guidelines and rules to follow from time to time too.
|
||||
|
||||
There's probably other projects I was involved with that I have
|
||||
forgotten. If any come to mind, I'll probably do a follow up post about
|
||||
them. And to any wondering about Total Block SMP, that's something I
|
||||
will be discussing later.
|
||||
91
content/posts/nodemc-developer-log-number-something.md
Normal file
91
content/posts/nodemc-developer-log-number-something.md
Normal file
|
|
@ -0,0 +1,91 @@
|
|||
---
|
||||
title: NodeMC Developer Log Number Something
|
||||
date: 2016-02-10
|
||||
---
|
||||
|
||||
#### A more developery post
|
||||
|
||||
NodeMC has changed a lot from what I envisioned in the
|
||||
beginning. When I first began development, nearly three months ago now
|
||||
(and about 52 git commits), I had envisioned a single product,
|
||||
everything packaged into one executable and probably wouldn't be used by
|
||||
anyone but me and one or two of my friends. However, I quickly found
|
||||
myself leaning towards something very... different.
|
||||
|
||||
It started when I started looking for ways to package NodeMC. My plan
|
||||
was to develop a full dashboard then open the source up and provide a
|
||||
few binaries. I had a silly idea it would be a quick project. I started
|
||||
in December, my first git commit dated the 17th (although I think I
|
||||
started on the 16th). I thought about it as a complete thing, dashboard
|
||||
and whatnot all packed into one executable. The first thing that moved
|
||||
my direction to the one I'm going in now was the fact that I could not
|
||||
figure out how to package other files into my executable made with
|
||||
[EncloseJS](http://enclosejs.com/). I
|
||||
made the decision to instead allow people to make their own dashboards
|
||||
and apps around the application.
|
||||
|
||||
|
||||
|
||||
When looking for investors, it came down to the Minecraft hosts I'd used
|
||||
before and knew they used the old Multicraft dashboard. I have nothing
|
||||
against Multicraft -- I think it's a pretty good dashboard, and the
|
||||
recent UI refresh makes it look much better. However I knew for a fact
|
||||
several hosts didn't upgrade, so I asked them first. I wanted to sell
|
||||
NodeMC to a host and develop it for them exclusively. My first target
|
||||
was ImChimp, whose owner [Alex](https://twitter.com/AlexHH25)
|
||||
has given me support in the past (and helped run the infamous
|
||||
server-that-shall-not-be-named). Unfortunately, he wasn't interested,
|
||||
and who can blame him, because at the time I had a very rudimentary
|
||||
demo.
|
||||
|
||||
https://www.youtube.com/watch?v=25ZVtFHwiCE
|
||||
|
||||
I did a bit more work and eventually was able to show off a much more
|
||||
refined version to James from [GGServers](https://ggservers.net).
|
||||
He was interested, and invested some money into the project to pay for a
|
||||
VPS to use for testing and hosting the [nodemc.space](https://nodemc.space)
|
||||
website, and a domain that was on sale (and would lead to my decision
|
||||
for major release names). I can confidently say that without his
|
||||
investment NodeMC would have probably been left as abandonware on
|
||||
GitHub.
|
||||
|
||||
Also thanks to James, I was given a list of things that are essential
|
||||
for Minecraft server dashboards, especially if you want to have
|
||||
multi-server hosts using it. This included custom jar files, file
|
||||
manipulation, logins with authentication, and more. Taking this list, I
|
||||
worked hard to implement the features I needed. Below is the playlist
|
||||
for all my dev logs.
|
||||
|
||||
https://www.youtube.com/watch?v=V-K8A6zQam0
|
||||
|
||||
It's been an interesting few months. I've learned many things about
|
||||
developing things in Node.js, from methods to the limits of the
|
||||
JavaScript language.
|
||||
|
||||
Since the beginning of this month, I've been making a huge effort to
|
||||
make MultiNodeMC work, building it out with logins, setup pages, server
|
||||
management, and everything else a server host admin needs. A very
|
||||
interested aspect that I've never given much thought is login and
|
||||
authentication, storing passwords, and keeping it all *secure*. A huge
|
||||
shoutout to [Oliver](https://www.oliverdunk.com/) for giving pointers on how to cut down on security
|
||||
vulnerabilities. He encouraged me to implement the API key feature for
|
||||
NodeMC to prevent unauthorized access of files.
|
||||
|
||||
Recently, and what made me rethink my methods of distributing the
|
||||
binaries, was my EncloseJS license key recently ran out. I have been
|
||||
looking at [nexe](https://github.com/jaredallard/nexe) as an alternative, which while it works (and seems to
|
||||
be slightly better at binary compression) isn't great because when I
|
||||
deployed it onto the VPS, it produced an error saying that glibc wasn't
|
||||
the correct version. This made me pause and wonder what on Earth I'm
|
||||
getting into. To clarify, with EncloseJS, you literally just need to
|
||||
send out the binary (and any files not packed into it), not worrying too
|
||||
much about dependencies because there are pretty much... none. That
|
||||
said, I believe nexe may be the way forward for me, and I'll be working
|
||||
on compiling it for all the distributions that I need to.
|
||||
|
||||
A question I've been asked quite a bit is **will you open-source this**?
|
||||
The answer is... no, not yet. I'll be opening up CORE (the basic
|
||||
application) around the time version 1.4.0 of NodeMC is released. I have
|
||||
no plans on open-sourcing MultiNodeMC at this time, however if I ever
|
||||
abandon the project I promise to release the full sourcecode to the
|
||||
public.
|
||||
53
content/posts/part-1-the-android-twitter-client-showdown.md
Normal file
53
content/posts/part-1-the-android-twitter-client-showdown.md
Normal file
|
|
@ -0,0 +1,53 @@
|
|||
---
|
||||
title: (Part 1) The Android Twitter Client Showdown
|
||||
date: 2016-12-06
|
||||
---
|
||||
|
||||
#### Falcon Pro, Talon, Flamingo and Fenix go head to head
|
||||
|
||||
I've been using Twitter for a long time now. I first
|
||||
signed up in October of the year 2010, four years after the initial
|
||||
launch. I've used is fairy regularly, with a total of 14,800+ tweets and
|
||||
have met a fairly wide range of people on the platform. I don't claim to
|
||||
be an expert, or even well know on the platform (276 followers is hardly
|
||||
"famous"). But, over the years, I have garnered much experience with
|
||||
different Twitter clients, starting with the web client as it was back
|
||||
in 2010, then moving to the official Twitter app on my old 1st
|
||||
generation iPad (no, not pro or anything... 1st gen iPad). Somehow I
|
||||
stumbled onto Tweetbot, which became my defacto (and still is, if I used
|
||||
iOS) Twitter client for iOS.
|
||||
|
||||
But back to the point. Over the next few weeks, or indeed months because
|
||||
I have a busy few coming up, I will be taking a few Android Twitter
|
||||
clients for a spin: [Talon](https://play.google.com/store/apps/details?id=com.klinker.android.twitter_l), [Flamingo](https://play.google.com/store/apps/details?id=com.samruston.twitter), [Falcon Pro 3](https://play.google.com/store/apps/details?id=com.jv.materialfalcon&hl=en), and [Fenix](https://play.google.com/store/apps/details?id=it.mvilla.android.fenix). All three of these apps offer fast, customizable
|
||||
experiences for Twitter, perhaps not with features on par with the
|
||||
official Twitter app, but you can blame the fact Twitter is locking down
|
||||
their API big time
|
||||
\[[Forbes](http://www.forbes.com/sites/ianmorris/2014/08/20/twitter-is-destroying-itself/#77a6716971b7),
|
||||
[ITWorld](http://www.itworld.com/article/2712336/unified-communications/the-death-of-the-twitter-api-or-a-new-beginning-.html)\].
|
||||
|
||||
My methodology is pretty straightforward. During the month of December,
|
||||
I will use each one for one week, testing and prodding each one to
|
||||
unlock the depths. Then, once all (four) have gone through the gauntlet,
|
||||
I will then allow myself the freedom of choice -- whichever one I find
|
||||
myself using the most will be the "winner".
|
||||
|
||||
#### Initial Impressions
|
||||
|
||||
All four of these support multiple accounts, however with Falcon Pro
|
||||
there is a small caveat, which is for each account you want to add you
|
||||
are required to purchase a new "account slot", which is about \$2. The
|
||||
initial purchase to add one account is on par with the rest of the apps,
|
||||
about \$5, Talon coming in at \$3.99, Fenix at \$6.49, and Flamingo
|
||||
coming in at \$2.79, the cheapest and also the newest of the four (all
|
||||
prices USD). Each one features material design, interestingly enough in
|
||||
a variety of styles. Each app has it's own customization, each with it's
|
||||
own advantages. Flamingo feels the most tweakable, letting you set your
|
||||
own colours for basically everything. Falcon Pro is by far the least
|
||||
customizable, however that is not necessarily a bad thing depending on
|
||||
your use case and how much you enjoy fiddling with settings.
|
||||
|
||||
Album of each Twitter client's interface
|
||||
|
||||
> "All life is an experiment. The more experiments you make the
|
||||
> better." -- Ralph Waldo Emerson
|
||||
71
content/posts/part-2-acts-flamingo.md
Normal file
71
content/posts/part-2-acts-flamingo.md
Normal file
|
|
@ -0,0 +1,71 @@
|
|||
---
|
||||
title: (Part 2) ATCS --- Flamingo {#part-2-atcs-flamingo .p-name}
|
||||
date: 2016-12-08
|
||||
---
|
||||
|
||||
Flamingo is a relatively new Twitter client, created by
|
||||
Sam Runston. It goes for \$2.79USD on the Google Play store, and
|
||||
frankly, is a solid Twitter client. Battery performance is fine, and
|
||||
performance is great.
|
||||
|
||||
#### Customizability
|
||||
|
||||
It is a fantastic app for Twitter, and it one of the more customizable
|
||||
clients if you like that sort of thing. You can tweak all the individual
|
||||
colours, or pick from a pre-made theme. You can change the fonts, how
|
||||
and where the pages are and look, and a whole lot more (actually while
|
||||
writing this review I found a way to turn off the giant navbar at the
|
||||
top, so bonus points!) through the settings. It might seem a bit
|
||||
overwhelming, and for the most part I left it with the default theme
|
||||
with some small tweaks.
|
||||
|
||||
For you night mode lovers, there is a beautiful implementation here. You
|
||||
can tweak the highlight colour to your liking and also the background,
|
||||
between dark, black, and "midnight blue". Of course, you can also set a
|
||||
timeframe for when you want this mode enabled -- one slightly annoying
|
||||
thing is you can't have it enabled all the time, however the theming
|
||||
options available should compensate for that fact.
|
||||
|
||||
#### Syncing
|
||||
|
||||
Retrieving tweets from Twitter's servers was always very snappy and
|
||||
fast, and I noticed to real performance hit in terms of battery or CPU
|
||||
usage when having tweet streaming on. I definitely recommend you turn it
|
||||
on -- I did not test it with background syncing enabled, and didn't
|
||||
really see any need to turn it on during my week with the app. There is
|
||||
Tweet Marker support, which comes in handy if you use clients, and I did
|
||||
leave it enabled (as I usually do).
|
||||
|
||||
There is a built-in proxy server setting, which is nice if you want to
|
||||
browse only Twitter using a proxy server. There are also several other
|
||||
options for turning off all retweets or replies, disabling auto refresh
|
||||
on startup and tweeting, and even has a setting for TeslaUnread so you
|
||||
can pick if you'd like to see unread notifications or tweets in your
|
||||
timeline (I assume you'll need to enable background sync for this to
|
||||
work properly.
|
||||
|
||||
#### Notifications
|
||||
|
||||
Notifications, as with any third party Twitter app I've tried, were slow
|
||||
to come in but seemed to be much more quick when the app was recently
|
||||
launched. I don't know if this is a Twitter API restriction or just an
|
||||
Android oddity, but I'm willing to guess it has to do with Twitter's
|
||||
rate limiting. Regardless, plenty of options here. You can enable
|
||||
notifications for individual accounts, as well as which notifications to
|
||||
show for each account (mentions, DMs, new followers, etc). There are
|
||||
also options to enable notifications only from verified accounts, if you
|
||||
interact with those enough, and allowing you to see which account
|
||||
received the notification, which as a multi-account user I left on.
|
||||
|
||||
#### Other notes
|
||||
|
||||
I love Flamingo so much -- the number of options it gives you to make
|
||||
your setup truly unique is astounding. Individual themes per account,
|
||||
*alternate app icons*, composition notifications, there is so much you
|
||||
can do with this app. I have some minor issues, like it confusing my
|
||||
accounts timelines, direct messages, or notifications, but overall it is
|
||||
a solid app that I highly recommend to those who want to get the
|
||||
absolute most out of their Twitter client.
|
||||
|
||||
[Get Flamingo on the Google Play
|
||||
Store -- \$2.79](https://play.google.com/store/apps/details?id=com.samruston.twitter&hl=en)
|
||||
74
content/posts/porting-websites-to-jekyll.md
Normal file
74
content/posts/porting-websites-to-jekyll.md
Normal file
|
|
@ -0,0 +1,74 @@
|
|||
---
|
||||
title: Porting Websites to Jekyll
|
||||
date: 2016-01-07
|
||||
---
|
||||
|
||||
#### Why on Earth use SSI...
|
||||
|
||||
Jekyll, to the uninitiated, is a static site generator for websites. Instead of using PHP include statements or SSI, it generates all the pages into plain-jane HTML. It uses a fairly straightforward file structure, making most projects very clean and nice to work with. I've personally used it for the [NodeMC](http://nodemc.space) website and the new [floorchan.org](https://floorchan.org) site, and have absolutely loved it. So how can you convert your website to use Jekyll?
|
||||
|
||||
I'll be using Strata from HTML5Up.net ([link](http://html5up.net/strata))
|
||||
to build a very simple and quick static page blog. This shouldn't take
|
||||
long. (I'm also assuming you have Jekyll installed, if not here's a
|
||||
[quick start guide](https://jekyllrb.com/docs/quickstart/).
|
||||
|
||||
First, extract the files from the zip. We'll need to create a few files
|
||||
for Jekyll to work. We need the following:
|
||||
|
||||
```
|
||||
_includes/
|
||||
_layouts/
|
||||
_config.yml
|
||||
```
|
||||
|
||||
Inside the \_config.yml file, we'll need a few things just to make sure
|
||||
Jekyll understands us, and maybe for future use. A simple setup would
|
||||
look like this:
|
||||
|
||||
```yaml
|
||||
name: Strata
|
||||
description: A template ported to Jekyll
|
||||
```
|
||||
|
||||
Let's now focus on the \_layouts/ directory. In here is where your
|
||||
templates will go for dictating how a page will look. You'll need to
|
||||
take your header and any static components you want to share across all
|
||||
pages and place them in here, like navbars, footers, etc. Where you want
|
||||
the content to go, you add {{content}}, which will pull the content from
|
||||
the file and place it there on the generated page. It is recommended you
|
||||
name this 'default.html' for easier referencing to it. Now you can go
|
||||
into your index.html in the root of your project and put in your
|
||||
content. You need to declare a title (more on this in a second) and a
|
||||
layout to use. Enclose the lines between three dashes. Here's an
|
||||
example.
|
||||
|
||||
```markdown
|
||||
---
|
||||
title: Strata
|
||||
layout: default
|
||||
---
|
||||
|
||||
lorem ipsum
|
||||
|
||||
```
|
||||
|
||||
And voila! You have ported your website over to Jekyll. You can run
|
||||
'jekyll serve' to run a server on port :4000 to preview your website,
|
||||
and 'jekyll build' to build the website to a static format to a \_site/
|
||||
directory.
|
||||
:::
|
||||
|
||||
|
||||
|
||||
There is of course quite a bit more you can do with Jekyll, like
|
||||
creating blogs and such, but maybe I'll cover that later -- or maybe
|
||||
not at all, because it seems pretty well documented online.
|
||||
|
||||
The advantage of using Jekyll should be fairly obvious -- because it
|
||||
generates HTML pages, it requires less processing overhead than PHP or
|
||||
SSI. It also means that there are no entry points for SQL injections or
|
||||
any of those nasty things. And one of the biggest advantages in my mind
|
||||
is the layout system, so you can quickly change something across all
|
||||
pages.
|
||||
|
||||
\~gabriel
|
||||
66
content/posts/python-flask-logins.md
Normal file
66
content/posts/python-flask-logins.md
Normal file
|
|
@ -0,0 +1,66 @@
|
|||
---
|
||||
title: Python / Flask Logins
|
||||
date: 2017-02-22
|
||||
---
|
||||
|
||||
#### This was fun! \*twitch\*
|
||||
|
||||
Bloody hell, where do I start...So I recently got back
|
||||
from a two week vacation down to LA (Disneyland) and then further south
|
||||
to Mexico. During those two weeks I did little to no coding, which
|
||||
greatly relaxed me and allowed me to think about what my goals with my
|
||||
many projects were.
|
||||
|
||||
And then I got home. And decided that the best thing to do (besides
|
||||
getting a violent cold) was to start work on a login system for
|
||||
Platypus. You know, so that admins can edit servers and whatnot. Oh boy
|
||||
are we in for some fun.
|
||||
|
||||
#### Initial Approach
|
||||
|
||||
At first I wanted to use Flask-Login, because that seemed like the
|
||||
logical way of doing things. It integrated with Flask, which is
|
||||
fantastic because I use that framework for literally everything (sorry
|
||||
Django, not feeling you yet). It (seemed) to provide an easy way to
|
||||
handle restricting views to logged in users. And thus I set out.
|
||||
|
||||
The first thing I noticed was that, like Flask, Flask-Login assumes
|
||||
nothing about your stack or how you should implement things. It requires
|
||||
you to write your own class for users and implement methods for
|
||||
retrieving users and passwords from a database, and also validating
|
||||
users login details. And then it hit me. Flask-Login is for *session*
|
||||
management, not *user* management. Back to the drawing board, slightly
|
||||
red faced when I realised what I was doing wrong.
|
||||
|
||||
#### IYWIDP, DIY
|
||||
|
||||
**I**f **y**ou **w**ant **i**t **d**one **p**roperly, **d**o **i**t
|
||||
**y**ourself. And so I did. I grabbed bcrypt's Python implementation and
|
||||
started writing my own system that relies on old school cookies as
|
||||
authentication. There were some false starts, but I eventually rigged
|
||||
together something that works, albeit with duct tape. What happens is
|
||||
thus. First, user requests /admin, which is obviously not a route we
|
||||
want unrestricted. So Flask grabs a cookie the browser provides and
|
||||
checks it against the current session token internally. If the two don't
|
||||
match or the cookie is blank, you're redirected to a login screen. The
|
||||
login form POSTS the data to the login route, which compares the passed
|
||||
password the the encrypted, salted and hashed password stored (as most
|
||||
logins do). Then, the function returns a unique key (actually a bcrypt
|
||||
salt) that acts as the session token. Cookie is set, user is sent to
|
||||
admin page. Brilliant!
|
||||
|
||||
Obviously there are some drawbacks that are not entirely intentional.
|
||||
For one, only one user can be auth'd at a time. This isn't a
|
||||
particularly troublesome problem in my deployment, however it's
|
||||
definitely not ideal. Also the session key is a bcrypt salt
|
||||
stringified -- this looks a bit funky but was a quick hacky way to
|
||||
generate a pseudo-random key. It's never used for anything beyond
|
||||
authenticating the browser.
|
||||
|
||||
*Hopefully it's secure enough.*
|
||||
|
||||
Now anyone who wants to have a crack at breaking the login, go right
|
||||
ahead, I won't stop you. Hell, I encourage it, and file issues as you
|
||||
see fit.
|
||||
|
||||
[Platypus on GitHub](https://github.com/ggservers/platypus)
|
||||
|
|
@ -0,0 +1,57 @@
|
|||
---
|
||||
title: Samsung Could Take Over The Digital Assistant Market
|
||||
date: 2017-08-06
|
||||
---
|
||||
|
||||
#### Bixby on phones is just the beginning.
|
||||
|
||||
The world was shaken when Samsung decided to roll out
|
||||
their own digital assistant on their flagship Galaxy S8 phones. As in,
|
||||
it was shaken by the collective groan that the tech community let loose
|
||||
upon learning that it would even have it's own, dedicated button. But
|
||||
there's something else I believe it lurking beneath the surface.
|
||||
|
||||
Samsung is an enormous company, making everything from phones to vacuum
|
||||
cleaners to dishwashers. Notable missing, however, is any indication of
|
||||
a competitor to Amazon Echo, Google Home or Apple's newly announced
|
||||
HomePod. Granted -- Bixby is fairly new, and is still learning. However
|
||||
given the wide range of products Samsung offers, the conclusion that is
|
||||
easy to draw is that they are planning on putting Bixby into their own
|
||||
home appliances, for a *truly* "smart" home.
|
||||
|
||||
Bixby itself is a fairly standard first generation virtual assistant. It
|
||||
can answer questions and control phone functions fairly well (including
|
||||
installing apps and changing system settings), but when put head to head
|
||||
with Google Assistant or Siri it falls a bit flat (you can check out
|
||||
MKBHDs comparison video [here](https://www.youtube.com/watch?v=BkpAro4zIwU)). The interface is very Samsung, not unattractive but
|
||||
not my personal taste. I especially like the Google Now-like interface
|
||||
(which it actually replaces on the S8), and believe it looks better if
|
||||
not as good as Google Now itself (Pixel XL owner here). However the
|
||||
interaction with the assistant itself definitely needs some work before
|
||||
I would consider it on par with it's competitors.
|
||||
|
||||
Already, many of their appliances are going "smart". They tout their
|
||||
smart fridges as being "Family Hubs" (trademarked, obviously), and run
|
||||
the Tizen operating system, an IoT operating system by the Linux
|
||||
Foundation. This means that they're already building off an open source
|
||||
project (which they already have a lot of experience with, launching
|
||||
phones running Tizen OS in India), and gives them a very, very good
|
||||
opportunity to implement Bixby. In everything. Smart ovens -- exist.
|
||||
Smart dishwashers -- why not. Would you like a smart vacuum cleaner?
|
||||
Consider it done. And they could all be running Bixby when Samsung
|
||||
decides it's smart enough.
|
||||
|
||||
Now -- the argument that Google, Amazon or Apple could take over your
|
||||
home with their products is there, however the problem with that is that
|
||||
they do not make every day appliances. Google has made some moves with
|
||||
Nest, and all three have assistant pods/bluetooth speakers, but it would
|
||||
take years for them to catch up to Samsung in terms of brand recognition
|
||||
in the appliances market. Not everyone needs a Google Home, but most
|
||||
people need a fridge, and that might happen to come with Tizen and
|
||||
Bixby. The average person may not have an Amazon Echo, but they'll
|
||||
probably have an oven, dishwasher, laundry machine... Perhaps not all,
|
||||
but at least one. And Samsung is well established.
|
||||
|
||||
So look forward to finally having a completely mic'd up home, courtesy
|
||||
of Samsung, listening, learning, adapting and assisting you every day.
|
||||
Whether or not it explodes (in popularity) we will see.
|
||||
29
content/posts/saving-the-link-shortner.md
Normal file
29
content/posts/saving-the-link-shortner.md
Normal file
|
|
@ -0,0 +1,29 @@
|
|||
---
|
||||
title: Saving the Link Shortner (Quick Post)
|
||||
date: 2015-10-30
|
||||
---
|
||||
|
||||
#### Aka a very silly mistake
|
||||
|
||||
You may remember the link shortner I wrote about in a past blog post.
|
||||
Well, I fixed an issue where it couldn't decide if a link was http://,
|
||||
https://, or just blank. Here's what I did.
|
||||
|
||||
Basically, had my strpos() in the wrong order. You need the haystack
|
||||
*first*, not second. That was an issue. Here's the correct code:
|
||||
|
||||
```php
|
||||
if(strpos($link[0][ 'actual '], 'http://') == false || strpos($link[0]['actual'], 'https://') == false){
|
||||
header( 'Location: '.$link[0]['actual']);
|
||||
}
|
||||
```
|
||||
|
||||
And then, of course, the little else statement in case it doesn't match:
|
||||
|
||||
```php
|
||||
}else{
|
||||
header('Location: http://'.$link[0]['actual']);
|
||||
}
|
||||
```
|
||||
|
||||
I do love PHP.
|
||||
65
content/posts/state-of-the-union.md
Normal file
65
content/posts/state-of-the-union.md
Normal file
|
|
@ -0,0 +1,65 @@
|
|||
---
|
||||
title: State of the Union
|
||||
date: 2017-10-26
|
||||
---
|
||||
|
||||
#### Where are the projects at?
|
||||
|
||||
I have a lot of projects on my plate right now. While
|
||||
also a full-time student, I am also working on expanding my portfolio
|
||||
and knowledge for the real world, which means a lot of projects.
|
||||
|
||||
My current project I'm focusing on is the podcast hosting app written in
|
||||
Go, named [**Pogo**](https://pogoapp.net). It's a straightforward CMS for managing podcast
|
||||
episodes, and automatically generates an RSS feed. It is more than
|
||||
stable in the current release, and I'd personally feel confident using
|
||||
it in production (your mileage may vary). Pogo currently features
|
||||
multiple user support, a flat directory structure for storing episodes
|
||||
alongside their respective shownotes, *mostly* correct RSS (few bugs to
|
||||
iron out, but all readers I have tested manage it fine), and a rich
|
||||
admin interface built out in Vue.js, which includes custom CSS and
|
||||
episode management.
|
||||
|
||||
I am currently working on the user management aspect of Pogo,
|
||||
implementing a much more sane method of storing and modifying user
|
||||
accounts, and looking into permissions for restricting certain
|
||||
functions. Previously, users were stored in a JSON file, became
|
||||
notoriously difficult to manage in Golang (not impossible however).
|
||||
Thus, I have moved to the much more portable SQLite3 -- I do have plans
|
||||
to explore the possibility of picking SQLite3 or MySQL (or MariaDB
|
||||
etc.), however I plan to focus most of my efforts on ensuring SQLite3
|
||||
compatibility. With this will come an admin interface for adding and
|
||||
managing users, which in the current release requires you to manually
|
||||
add them into the JSON file (and manually generate a bcrypt hash...).
|
||||
Once the users branch has been merged into the master branch, work will
|
||||
be done to rework the frontend to use Vue.js instead of plain
|
||||
JavaScript. I've also been really happy with the current traffic and
|
||||
outside contributions thanks to my efforts to promote it "organically"
|
||||
and Hacktoberfest, from which some contributors have found the project.
|
||||
|
||||
Another project I've been looking at again is
|
||||
[**Platypus**](https://getplatypus.io). The simple real time server usage monitor I wrote
|
||||
back at GGServers has been lying dormant for a long time, and I can't
|
||||
remember where I left off. It was ready to be deployed, but was not the
|
||||
focus of the company at the time and I ended up moving it back to my
|
||||
personal Github. I'm still very proud of the achievement of writing such
|
||||
a platform in Python, but I want to start rewriting it in Go. The
|
||||
reasons are twofold; one, I have become very familiar with Go in the
|
||||
past few months, and believe it could offer much better performance when
|
||||
it comes to scaling the application. It's never really been tested at
|
||||
the large scale it should have been, and I'm still a bit leery of the
|
||||
aspect. I do want to reach out to some larger companies to see if they'd
|
||||
be interesting in giving me a hand with this. Regardless, a rewrite in
|
||||
Go + Vue.js is definitely on my mind, and improving the AOR interface so
|
||||
anyone can write their own version in whatever they already have on
|
||||
their server.
|
||||
|
||||
And I continue to work on articles for [**Git Galaxy**](https://gitgalaxy.com),
|
||||
writing about whatever comes to mind when it comes to open source
|
||||
software. I'm currently working on a Hacktoberfest experience roundup,
|
||||
and researching another opinion piece along the lines of the [Opening
|
||||
Schools to the
|
||||
Students](https://gitgalaxy.com/opening-schools-to-the-students/). Analytic numbers are looking solid, and I am more
|
||||
than happy with how it's turning out.
|
||||
|
||||
That is the state of my projects.
|
||||
31
content/posts/the-importance-of-income.md
Normal file
31
content/posts/the-importance-of-income.md
Normal file
|
|
@ -0,0 +1,31 @@
|
|||
---
|
||||
title: The Importance of Income
|
||||
date: 2015-11-02
|
||||
---
|
||||
|
||||
#### It's scary how much a small number can mean
|
||||
|
||||
I'm preparing myself to start launching a long-term project that I have
|
||||
been working on for the past few months. It's something I'm going to be
|
||||
doing on the side and I don't hope to earn much of a living off
|
||||
it -- for one simple reason. Per month, if the service takes off, I'd
|
||||
have to pay around $108.88USD.
|
||||
|
||||
I don't really know how that compares to other startups. But considering
|
||||
it's a (so far) one man operation and I'm not expecting to make a living
|
||||
off it, I think it's rather cheap compared to something like
|
||||
[Twitter](http://www.amazon.ca/Hatching-Twitter-Story-Friendship-Betrayal/dp/1591847087). Also, about $99 of that wouldn't need to be accounted for (pun unintended) until I hit around 500 users, which would mean at least the first couple of months would only cost me \$9.88, out of pocket. The \$99, by the way, would be for the 'Startup' level of [UserApp.io](https://www.userapp.io/), which I am using for user accounts and payments -- I could ditch it in favor of my own user system (and in fact at some point I plan to), but for now I don't want to focus on that, and therefore must pay the price when I hit the user cap.
|
||||
|
||||
So how can I make the project self-sufficient? Well, donations will be a
|
||||
big part of it. There will be two ranks -- a $5 and a $15 -- that will hopefully be able to manage the upkeep cost. These will also be
|
||||
monthly subscriptions, which means if as little as 20 users (out of the
|
||||
500 cap) bought the $5 rank, that would be $100 I wouldn't have to
|
||||
worry about. A minimum of 8 people buying the $15 rank would make the
|
||||
entire project entirely self-funded, at $120 a month of income.
|
||||
|
||||
Now this is making a lot of assumptions, such as if the project will
|
||||
actually take off, or if 20 people in 500 donate, but I think it's a
|
||||
decent assumption that it will work.
|
||||
|
||||
Another important factor is investors, but I can cover that another
|
||||
time.
|
||||
53
content/posts/the-tvdb-google-app-script.md
Normal file
53
content/posts/the-tvdb-google-app-script.md
Normal file
|
|
@ -0,0 +1,53 @@
|
|||
---
|
||||
title: The TVDB Google App Script
|
||||
date: 2016-12-06
|
||||
---
|
||||
|
||||
#### Let's learn something new!
|
||||
|
||||
My girlfriend Becky and I enjoy watching TV shows
|
||||
together. So much so, in fact, that we've started putting together a
|
||||
spreadsheet of the shows the need to binge watch together. So just for
|
||||
the hell of it, I threw together a rather basic (and messy) Google App
|
||||
Script that lives in the spreadsheet, which pulls information from [The
|
||||
TVDB](https://thetvdb.com/) regarding
|
||||
how many episodes there are and how long it would take to binge watch
|
||||
all the shows (roughly).
|
||||
|
||||
Some things I learned while working in the Google App Script IDE. First,
|
||||
tabs are only two spaces, instead of the usual four I work with in
|
||||
Python. Which messed me up slightly when I first started, but I go much
|
||||
more used to it. Second, it's just JavaScript, really. I expected some
|
||||
sort of stripped down programming language but it's really just a
|
||||
slightly tweaked JS environment, with some functions that allow you to
|
||||
interact with Google Docs/Sheets/Forms etc. And finally, I learned just
|
||||
how useful Google App Scripts can be -- I never really used them, and
|
||||
believed them to be a waste of time to learn. Alas, I was wrong, my
|
||||
elitist thinking getting the better of me.
|
||||
|
||||
So let's talk about the actual script. You can find the whole thing in
|
||||
the Gist below, a slightly tidied up and revised version. You'll need an
|
||||
API key from The TVDB, and I highly recommend you check out [their API
|
||||
docs](https://api.thetvdb.com/swagger) so you know exactly what sort of info and routes
|
||||
we're using.
|
||||
|
||||
Essentially, what happens in this. First, we search (using
|
||||
`searchTvdb(show, network)`) for the specific show, using the network to
|
||||
filter out results in case there are multiple shows with the same name.
|
||||
Next, we take the showId it returns and query TVDB for the info
|
||||
corresponding to the show -- we're most interested in the average
|
||||
runtime from this query. We also ask TVDB for the summary of the
|
||||
episodes, which returns the number of seasons, episodes aired, and so
|
||||
on. We aggregate all this data into one clump of data and then throw it
|
||||
into the spreadsheet.
|
||||
|
||||
It's very inefficient, I realize that. There are plenty of things I
|
||||
could probably improve performance wise, however it works fine. I expect
|
||||
the more shows in the spreadsheet the longer it will take (about 12
|
||||
seconds with a 14 item list), but I'll refine a bit in the future.
|
||||
|
||||

|
||||
|
||||
> "If everyone demanded peace instead of another television set, then
|
||||
> there'd be peace." -- [**John
|
||||
> Lennon**](https://www.goodreads.com/author/show/19968.John_Lennon) **(Probably)**
|
||||
57
content/posts/things-twitter-could-do-better.md
Normal file
57
content/posts/things-twitter-could-do-better.md
Normal file
|
|
@ -0,0 +1,57 @@
|
|||
---
|
||||
title: Things Twitter Should Do Better
|
||||
date: 2016-01-14
|
||||
---
|
||||
|
||||
#### Just some notes...
|
||||
|
||||
Twitter is going downhill (in my opinion). Since Jack
|
||||
Dorsey became CEO (again), there have been some... *interesting*
|
||||
additions. The number one, most useless thing they wasted their time on
|
||||
is **Twitter Moments**. Moments is basically a summary of media the
|
||||
people who follow have tweeted. I'd like to see some stats on how many
|
||||
people use it, and how many of those people clicked it either by
|
||||
accident or out of idle curiosity. I don't think it's something Twitter
|
||||
should have spent time developing -- perhaps their time would have been
|
||||
better spent improving their existing things, like making the Twitter
|
||||
mobile app more consistent or streamlining Twitter for Web -- or hell,
|
||||
even making TweetDeck nicer to use.
|
||||
|
||||
The official Twitter app for Android (not sure about iOS) is a mess. The
|
||||
most prominent issue I have is the fact that the top navigation bar will
|
||||
change what icons it has where, either when I switch between accounts or
|
||||
just restart the app. Their bottom nav is terrible too -- it will cycle
|
||||
between a clunky floating action button, a bar with a faux-text input
|
||||
and camera icon, and a three-section bar consisting of a new tweet,
|
||||
camera, and gallery icons. What is this? Why on Earth do we need three
|
||||
different nav styles -- that it *cycles between?!* I want to know both
|
||||
how and why this decision was made, if it can count as a decision.
|
||||
|
||||
I think the worst part of this whole Twitter app debacle is that they
|
||||
have people at Twitter who know how to do Twitter apps. The creator of
|
||||
[Falcon Pro](http://getfalcon.pro/)
|
||||
works at Twitter, and I consider his app an absolutely amazing Twitter
|
||||
experience. So how why is the experience so terrible? And why are they
|
||||
focusing on new things like an edit button (rumored), 10,000 character
|
||||
tweets (again, rumored), and **bloody Twitter Moments**.
|
||||
|
||||
#### So, Mr. Jack Dorsey, how could you make Twitter decent again?
|
||||
|
||||
First, take a step back. Remember what you envisioned Twitter being. No,
|
||||
not a text-only messaging system, that's a terrible idea, and remember
|
||||
how much debt Twitter was in after that. No, rather, take a step back
|
||||
and simplify. Cut out the 'features' you think are fantastic. Make it a
|
||||
140-character microblogging platform. Cut out anything that you can see
|
||||
any reason to have. Open up your API more and let devs work on what they
|
||||
want to. Why? Because people want and have freedom of choice. If they
|
||||
don't want to use the official Twitter app, fine. Let them use an
|
||||
unofficial one, an unofficial one that has actual access to something
|
||||
resembling an API, not extremely basic functions. And fix your own
|
||||
official apps, so people are actually tempted to use them. Keep the
|
||||
140-character limit, because it's a gimmick that worked. Return Likes to
|
||||
Favorites, because you're not Facebook, as much as you want to work
|
||||
there. Maybe fix up Tweetdeck so it's a little nicer to use, modernize
|
||||
the UI and make it flow. Promote the Falcon Pro author to a position
|
||||
where he can make some UI/UX suggestions and actually get heard.
|
||||
|
||||
And above all, *please don't kill the blue bird.*
|
||||
48
content/posts/watching-a-cryptocurrency-grow.md
Normal file
48
content/posts/watching-a-cryptocurrency-grow.md
Normal file
|
|
@ -0,0 +1,48 @@
|
|||
---
|
||||
title: Watching a Cryptocurrency Grow
|
||||
date: 2018-01-22
|
||||
---
|
||||
|
||||
#### GRLC is the only coin you'll ever need
|
||||
|
||||
Last weekend, a new cryptocurrency launched: Garlicoin, a fork of
|
||||
Litecoin based around garlic bread. It may seem silly at first, but keep
|
||||
in mind that sometimes "silly" coins can have a huge impact, like the
|
||||
time [Dogecoin sponsored a NASCAR
|
||||
racer](https://www.nascar.com/en_us/news-media/blogs/Off-Track/posts/doge-reddit-josh-wise-talladega-superspeedway-aarons-499.html). Regardless of what you may believe, it's always
|
||||
worth keeping an eye on meme coins (not memecoin, which is an actual
|
||||
coin).
|
||||
|
||||
Currently, it's Monday, the day after the release, and already the
|
||||
Garlicoin community is thriving, both on the incredibly active Discord
|
||||
and the /r/garlicoin subreddit. There is also /r/garlicmarket, which
|
||||
will be the focus of much of this post. Regardless, this is very much a
|
||||
community driven coin, with a number of mining pools already available
|
||||
([see here](http://pools.garlicoin.fun/)) and about 297063 coins available so far. The market
|
||||
cap is at 69 million, so it should be interesting to see how that plays
|
||||
out. It's also been pretty interesting to see the newcomers to the
|
||||
cryptocurrency space asking questions and figuring things out, like why
|
||||
having a pool with more than 51% of the total hashing power [is a bad
|
||||
thing](https://learncryptography.com/cryptocurrency/51-attack).
|
||||
|
||||
#### So how valuable is Garlicoin right now? Should I be investing into it?
|
||||
|
||||
First, it's actually doing pretty well in terms of value. The
|
||||
/r/garlicmarket subreddit seems to have established that 1GRLC (1
|
||||
garlicoin) is about equivalent to a whole 1USD. This will likely
|
||||
fluctuate over time, but considering how quickly they can be mined and
|
||||
the current circulating supply it's pretty impressive. It's been pretty
|
||||
impressive to watch new trade offers be posted offering 1USD for 1GRLC.
|
||||
You can even [buy lockpicks with it if you want](https://www.reddit.com/r/GarlicMarket/comments/7s8bkw/shop_lock_picks_and_security_tools_usa_global/), on the same exchange rate.
|
||||
|
||||
As for whether or not you should invest now, I would say absolutely.
|
||||
With the way things are currently going, 1USD being roughly 1GRLC, it
|
||||
may be better to mine for them rather than trade or buy outright and
|
||||
watch the price closely, because with cryptocurrency you never really
|
||||
know what's going to happen.
|
||||
|
||||
If you want to get started, head over to the [official website,](http://garlicoin.io/) where
|
||||
you can find wallets and links to getting mining.
|
||||
|
||||
My GRLC (vanity) address if you're interested:
|
||||
GMeMMdtqRTUF7V9FmsdtuFcej69DnyKhnY
|
||||
69
content/posts/where-nodemc-is-headed.md
Normal file
69
content/posts/where-nodemc-is-headed.md
Normal file
|
|
@ -0,0 +1,69 @@
|
|||
---
|
||||
title: Where NodeMC is headed.
|
||||
date: 2016-06-02
|
||||
---
|
||||
|
||||
#### aka the "SE Daily Follow-up Post"
|
||||
|
||||
I talked about where I wanted to take NodeMC on the
|
||||
Software Engineering Daily podcast last month. I also discussed a few
|
||||
things about the future of Minecraft, it becoming less of a game and
|
||||
more of a tool, and how NodeMC will help fulfil a need for quick and
|
||||
easy-to-deploy Minecraft servers.
|
||||
|
||||
Before we get into the future, let's talk about what's happening for
|
||||
NodeMC v6 (6.0.0). First and foremost, we've rewritten pretty much every
|
||||
aspect of NodeMC using the ES6 specifications, transforming the
|
||||
monolithic single-file-of-code into an agile and easy to scale platform
|
||||
of microservices. Not only does it mean I have to learn ES6, it also
|
||||
means it's much easier to add new features and API routes. We're adding
|
||||
an auto-updater (which you will be able to turn on or off hopefully),
|
||||
switching to using semver for versioning, and overhauling the plugin
|
||||
system with permissions and a better API to interface with the core.
|
||||
|
||||
We're also changing several of the routes to make more sense. Every
|
||||
route that has been implemented in version 5.0.0 or below is labelled
|
||||
'/v1/'. New routes introduced in v6.0.0 are '/v2/'. Routes that
|
||||
interface with the server are directed to '/server/', and so forth. Each
|
||||
of these routes are generated with Express and some fancy magic (Jared
|
||||
goes into it a bit more
|
||||
[here](https://medium.com/@jaredallard/why-i-moved-from-monolithic-backends-to-microservices-d9955b9464b2#.bexdzdpzw)) so that we can keep all the code clean.
|
||||
|
||||
So, back to the main topic of this post.
|
||||
|
||||
#### Where is NodeMC going?
|
||||
|
||||
The direction NodeMC is headed is being a software-as-a-service. I want
|
||||
to accommodate for the rapid change in direction of Minecraft, it
|
||||
becoming less of a game and more of a platform for creative works. We've
|
||||
seen it used as more than just a game before, with things like [the UN
|
||||
using Minecraft to re-develop neighbourhoods](http://www.polygon.com/2014/4/22/5641044/minecraft-block-by-block-united-nations-project) or it being [used for
|
||||
teaching](http://education.minecraft.net/minecraftedu/), and it makes me feel we're heading more in the
|
||||
direction of this sandbox game becoming a tool for both creative,
|
||||
educational and professional work.
|
||||
|
||||
NodeMC as a SaaS basically means this: Companies who want to quickly
|
||||
deploy and manage Minecraft servers will be able to quickly spin up
|
||||
Minecraft servers either through a user interface or their own UI. A
|
||||
typical example of this may be something like so.
|
||||
|
||||
Company A wants to design a new housing complex really quickly to show
|
||||
to some clients, and they feel Minecraft is the best way of doing that.
|
||||
They would visit the NodeMC website and hit the "New Server" button,
|
||||
picking the flat world preset with one or two plugins like WorldEdit.
|
||||
Once the designers are done their job, they run a command to zip the
|
||||
world file, save the zip to the cloud, and shut off the server. Company
|
||||
A can then spin up "viewing servers" that allow clients to log in and
|
||||
explore the project freely. Everything is stored in the cloud, and if
|
||||
Company A wants they can download the zip file or run the world through
|
||||
a processor first to export it to a 3D design program.
|
||||
|
||||
> TL;DR: Starts server for building at click of a button \> Builds
|
||||
> mockup \> Saves world to the cloud \> Viewing server deployed for
|
||||
> clients automatically.
|
||||
|
||||
Obviously this is not a small task, and required a *ton* more work on
|
||||
NodeMC. Right now v6 is focused on the ES6 rewrite, dashboard written in
|
||||
React, and the plugin system. I'm already drawing up v7 plans, which are
|
||||
going to help drive NodeMC in the direction I want to take it. And who
|
||||
knows, maybe this will go other unexpected directions.
|
||||
50
content/posts/why-new-social-media-fails.md
Normal file
50
content/posts/why-new-social-media-fails.md
Normal file
|
|
@ -0,0 +1,50 @@
|
|||
---
|
||||
title: Why New Social Media Fails
|
||||
date: 2017-06-16
|
||||
---
|
||||
|
||||
#### (for now)
|
||||
|
||||
We all know and love social media. In this day and age,
|
||||
it's almost impossible to avoid it. As social creatures we crave the
|
||||
satisfaction of being connected to so many people at once. But we also
|
||||
hate the platforms that are available -- Facebook is data hungry,
|
||||
Twitter has some bizarre developer policies and is rife with bots,
|
||||
reddit is a hive mind... the list goes on. So why can't we just make a
|
||||
new social platform that solves all these issues?
|
||||
|
||||
The sad truth is that incentivizing people to move to another platform
|
||||
is really difficult. We can observe this with something like Google
|
||||
Allo, which surged with popularity when it was announced but has
|
||||
apparently completely stalled in downloads (via [Android Police](http://www.androidpolice.com/2016/11/29/google-allo-hit-5-million-downloads-in-5-days-two-months-later-its-momentum-seems-utterly-stalled/)). A handful of people I talk to on a regular basis
|
||||
have it installed, but we also end up communicating a lot on Twitter,
|
||||
which defeats the purpose (I also have a sneaking suspicion I might be
|
||||
the only person they have on Allo)
|
||||
|
||||
> [](https://twitter.com/gmem_/status/870790497727422464)
|
||||
|
||||
> [](https://twitter.com/jaredallard/status/870790618238210048)
|
||||
|
||||
Unfortunately Facebook is no different. Despite my best efforts, for a
|
||||
lot of people including my bosses, it has pretty much completely
|
||||
replaced SMS. Facebook Messenger is the only messaging platform they
|
||||
use, and who can blame them -- it's a solid messaging app. And I say
|
||||
this with a hint of sarcasm
|
||||
([reddit](https://www.reddit.com/r/Nexus6P/comments/4jpcvt/absolutely_ridiculous_facebook_messenger_battery/), although I've seen some reports [suggesting they fixed it](http://mashable.com/2017/01/11/facebook-messenger-battery-drain/#jfK9Pvnv9iqP) recently).
|
||||
|
||||
And other social networks... have fared no better. The two biggest names
|
||||
out there, Facebook and Twitter, dominate. Startups have attempted to
|
||||
build better platforms -- I remember signing up for the beta of
|
||||
[App.net](https://en.wikipedia.org/wiki/App.net), which ended up shutting because the company simply
|
||||
ran out of money, due both to low adoption rates and low conversion of
|
||||
free customers to paying. Niche platforms have risen like
|
||||
[Mastodon](https://mastodon.social/about), which have potential but the adoption rate will be
|
||||
low and very niche.
|
||||
|
||||
Now there is a bright side to all this. There will always be a place for
|
||||
startup social platforms -- Remember, we all thought MySpace couldn't
|
||||
fail (and when was the last time you thought of *MySpace*?). There will
|
||||
be a time when Twitter doesn't manage to keep up with the times, or
|
||||
people wise up and ditch Facebook completely. I don't want to discourage
|
||||
people from exploring the potential of their twist on the idea, who
|
||||
knows what could happen.
|
||||
19
layouts/_default/list.html
Normal file
19
layouts/_default/list.html
Normal file
|
|
@ -0,0 +1,19 @@
|
|||
{{ define "main" }}
|
||||
<main>
|
||||
<article>
|
||||
<header>
|
||||
<h1>{{.Title}}</h1>
|
||||
</header>
|
||||
<!-- "{{.Content}}" pulls from the markdown content of the corresponding _index.md -->
|
||||
{{.Content}}
|
||||
</article>
|
||||
<ul>
|
||||
<!-- Ranges through content/posts/*.md -->
|
||||
{{ range .Pages }}
|
||||
<li>
|
||||
<a href="{{.Permalink}}">{{.Date.Format "2006-01-02"}} | {{.Title}}</a>
|
||||
</li>
|
||||
{{ end }}
|
||||
</ul>
|
||||
</main>
|
||||
{{ end }}
|
||||
8
themes/gs/layouts/404.html
Normal file
8
themes/gs/layouts/404.html
Normal file
|
|
@ -0,0 +1,8 @@
|
|||
{{ define "header" }}{{ partial "page-header.html" . }}{{ end }}
|
||||
{{ define "main" }}
|
||||
<article class="center cf pv5 measure-wide-l">
|
||||
<h1>
|
||||
This is not the page you were looking for
|
||||
</h1>
|
||||
</article>
|
||||
{{ end }}
|
||||
33
themes/gs/layouts/_default/baseof.html
Normal file
33
themes/gs/layouts/_default/baseof.html
Normal file
|
|
@ -0,0 +1,33 @@
|
|||
<!DOCTYPE html>
|
||||
<html lang="{{ $.Site.LanguageCode | default "en" }}">
|
||||
<head>
|
||||
<meta charset="utf-8">
|
||||
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1">
|
||||
<title>{{ block "title" . }}{{ with .Params.Title }}{{ . }} | {{ end }}{{ .Site.Title }}{{ end }}</title>
|
||||
<meta name="viewport" content="width=device-width,minimum-scale=1">
|
||||
<meta name="description" content="{{ with .Description }}{{ . }}{{ else }}{{if .IsPage}}{{ .Summary }}{{ else }}{{ with .Site.Params.description }}{{ . }}{{ end }}{{ end }}{{ end }}">
|
||||
{{ hugo.Generator }}
|
||||
{{/* NOTE: For Production make sure you add `HUGO_ENV="production"` before your build command */}}
|
||||
{{ if eq (getenv "HUGO_ENV") "production" | or (eq .Site.Params.env "production") }}
|
||||
<META NAME="ROBOTS" CONTENT="INDEX, FOLLOW">
|
||||
{{ else }}
|
||||
<META NAME="ROBOTS" CONTENT="NOINDEX, NOFOLLOW">
|
||||
{{ end }}
|
||||
|
||||
{{ if .OutputFormats.Get "RSS" }}
|
||||
{{ with .OutputFormats.Get "RSS" }}
|
||||
<link href="{{ .RelPermalink }}" rel="alternate" type="application/rss+xml" title="{{ $.Site.Title }}" />
|
||||
<link href="{{ .RelPermalink }}" rel="feed" type="application/rss+xml" title="{{ $.Site.Title }}" />
|
||||
{{ end }}
|
||||
{{ end }}
|
||||
<link rel="icon" href="data:image/svg+xml,<svg xmlns=%22http://www.w3.org/2000/svg%22 viewBox=%220 0 100 100%22><text y=%22.9em%22 font-size=%2290%22>🏳️🌈</text></svg>">
|
||||
<link rel="stylesheet" href="/css/styles.css">
|
||||
</head>
|
||||
|
||||
<body class="ma0 {{ $.Param "body_classes" | default "avenir bg-near-white"}}{{ with getenv "HUGO_ENV" }} {{ . }}{{ end }}">
|
||||
<main>
|
||||
{{ block "main" . }}{{ end }}
|
||||
</main>
|
||||
|
||||
</body>
|
||||
</html>
|
||||
15
themes/gs/layouts/_default/list.html
Normal file
15
themes/gs/layouts/_default/list.html
Normal file
|
|
@ -0,0 +1,15 @@
|
|||
{{ define "main" }}
|
||||
<article class="pa3 pa4-ns nested-copy-line-height nested-img">
|
||||
<section class="cf ph3 ph5-l pv3 pv4-l f4 tc-l center measure-wide lh-copy mid-gray">
|
||||
{{- .Content -}}
|
||||
</section>
|
||||
<section class="flex-ns flex-wrap justify-around mt5">
|
||||
{{ range .Paginator.Pages }}
|
||||
<div class="relative w-100 w-30-l mb4 bg-white">
|
||||
{{- partial "summary.html" . -}}
|
||||
</div>
|
||||
{{ end }}
|
||||
</section>
|
||||
{{- template "_internal/pagination.html" . -}}
|
||||
</article>
|
||||
{{ end }}
|
||||
30
themes/gs/layouts/_default/single.html
Normal file
30
themes/gs/layouts/_default/single.html
Normal file
|
|
@ -0,0 +1,30 @@
|
|||
{{ define "main" }}
|
||||
<div class="container">
|
||||
<div class="row">
|
||||
<div class="twelve columns">
|
||||
<h1>{{ default .Site.Title }}</h1>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
<div class="row">
|
||||
<div class="eight columns">
|
||||
<h2>{{- .Title -}}</h2>
|
||||
{{ with .Params.author }}
|
||||
<p>
|
||||
By <strong>
|
||||
{{ if reflect.IsSlice . }}
|
||||
{{ delimit . ", " | markdownify }}
|
||||
{{else}}
|
||||
{{ . | markdownify }}
|
||||
{{ end }}
|
||||
</strong>
|
||||
</p>
|
||||
{{ end }}
|
||||
<time {{ printf `datetime="%s"` (.Date.Format "2006-01-02T15:04:05Z07:00") | safeHTMLAttr }}>
|
||||
{{- .Date.Format "January 2, 2006" -}}
|
||||
</time>
|
||||
{{- .Content -}}
|
||||
</div>
|
||||
</div>
|
||||
{{ end }}
|
||||
|
||||
16
themes/gs/layouts/_default/taxonomy.html
Normal file
16
themes/gs/layouts/_default/taxonomy.html
Normal file
|
|
@ -0,0 +1,16 @@
|
|||
{{ define "main" }}
|
||||
<article class="cf pa3 pa4-m pa4-l">
|
||||
<div class="measure-wide-l center f4 lh-copy nested-copy-line-height nested-links nested-img mid-gray">
|
||||
<p>{{i18n "taxonomyPageList" .}}</p>
|
||||
</div>
|
||||
</article>
|
||||
<div class="mw8 center">
|
||||
<section class="flex-ns flex-wrap justify-around mt5">
|
||||
{{ range .Pages }}
|
||||
<div class="relative w-100 mb4 bg-white">
|
||||
{{ partial "summary.html" . }}
|
||||
</div>
|
||||
{{ end }}
|
||||
</section>
|
||||
</div>
|
||||
{{ end }}
|
||||
22
themes/gs/layouts/_default/terms.html
Normal file
22
themes/gs/layouts/_default/terms.html
Normal file
|
|
@ -0,0 +1,22 @@
|
|||
{{ define "main" }}
|
||||
{{ $data := .Data }}
|
||||
<article class="cf pa3 pa4-m pa4-l">
|
||||
<div class="measure-wide-l center f4 lh-copy nested-copy-line-height nested-links nested-img mid-gray">
|
||||
{{ .Content }}
|
||||
</div>
|
||||
</article>
|
||||
<div class="mw8 center">
|
||||
<section class="ph4">
|
||||
{{ range $key, $value := .Data.Terms }}
|
||||
<h2 class="f1">
|
||||
<a href="{{ "/" | relLangURL }}{{ $.Data.Plural | urlize }}/{{ $key | urlize }}" class="link blue hover-black">
|
||||
{{ $.Data.Singular | humanize }}: {{ $key }}
|
||||
</a>
|
||||
</h2>
|
||||
{{ range $value.Pages }}
|
||||
{{ partial "summary.html" . }}
|
||||
{{ end }}
|
||||
{{ end }}
|
||||
</section>
|
||||
</div>
|
||||
{{ end }}
|
||||
25
themes/gs/layouts/index.html
Normal file
25
themes/gs/layouts/index.html
Normal file
|
|
@ -0,0 +1,25 @@
|
|||
{{ define "main" }}
|
||||
<div class="container">
|
||||
<div class="row">
|
||||
<div class="twelve columns">
|
||||
<h1>{{ .Title | default .Site.Title }}</h1>
|
||||
</div>
|
||||
</div>
|
||||
|
||||
<div class="row">
|
||||
<div class="eight columns">
|
||||
{{- .Content -}}
|
||||
{{ range .Paginator.Pages }}
|
||||
<h2><a href="{{ .Permalink }}">{{ .Title }}</a></h2>
|
||||
<div class="nested-links f5 lh-copy nested-copy-line-height">
|
||||
{{ .Summary }}
|
||||
</div>
|
||||
{{ end }}
|
||||
<div class="pagination">
|
||||
{{- template "_internal/pagination.html" . -}}
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
</div>
|
||||
{{ end }}
|
||||
|
||||
18
themes/gs/layouts/page/single.html
Normal file
18
themes/gs/layouts/page/single.html
Normal file
|
|
@ -0,0 +1,18 @@
|
|||
{{ define "header" }}{{ partial "page-header.html" . }}{{ end }}
|
||||
{{ define "main" }}
|
||||
<div class="flex-l mt2 mw8 center">
|
||||
<article class="center cf pv5 ph3 ph4-ns mw7">
|
||||
<header>
|
||||
<p class="f6 b helvetica tracked">
|
||||
{{ humanize .Section | upper }}
|
||||
</p>
|
||||
<h1 class="f1">
|
||||
{{ .Title }}
|
||||
</h1>
|
||||
</header>
|
||||
<div class="nested-copy-line-height lh-copy f4 nested-links nested-img mid-gray">
|
||||
{{ .Content }}
|
||||
</div>
|
||||
</article>
|
||||
</div>
|
||||
{{ end }}
|
||||
21
themes/gs/layouts/post/list.html
Normal file
21
themes/gs/layouts/post/list.html
Normal file
|
|
@ -0,0 +1,21 @@
|
|||
{{ define "main" }}
|
||||
{{/*
|
||||
This template is the same as the default and is here to demonstrate that if you have a content directory called "post" you can create a layouts directory, just for that section.
|
||||
*/}}
|
||||
<article class="pa3 pa4-ns nested-copy-line-height nested-img">
|
||||
<section class="cf ph3 ph5-l pv3 pv4-l f4 tc-l center measure-wide lh-copy mid-gray">
|
||||
{{ .Content }}
|
||||
</section>
|
||||
<aside class="flex-ns flex-wrap justify-around mt5">
|
||||
{{ range .Paginator.Pages }}
|
||||
<div class="relative w-100 w-30-l mb4 bg-white">
|
||||
{{/*
|
||||
Note we can use `.Render` here for items just in this section, instead of a partial to pull in items for the list page. https://gohugo.io/functions/render/
|
||||
*/}}
|
||||
{{ .Render "summary" }}
|
||||
</div>
|
||||
{{ end }}
|
||||
</aside>
|
||||
{{ template "_internal/pagination.html" . }}
|
||||
</article>
|
||||
{{ end }}
|
||||
20
themes/gs/layouts/post/summary-with-image.html
Normal file
20
themes/gs/layouts/post/summary-with-image.html
Normal file
|
|
@ -0,0 +1,20 @@
|
|||
<article class="bb b--black-10">
|
||||
<a class="db pv4 ph3 ph0-l no-underline dark-gray dim" href="{{ .Permalink }}">
|
||||
<div class="flex flex-column flex-row-ns">
|
||||
{{ $featured_image := partial "func/GetFeaturedImage.html" . }}
|
||||
{{ if $featured_image }}
|
||||
<div class="pr3-ns mb4 mb0-ns w-100 w-40-ns">
|
||||
<img src="{{ $featured_image }}" class="db" alt="image from {{ .Title }}">
|
||||
</div>
|
||||
{{ end }}
|
||||
<div class="w-100{{ if $featured_image }} w-60-ns pl3-ns{{ end }}">
|
||||
<h1 class="f3 fw1 athelas mt0 lh-title">{{ .Title }}</h1>
|
||||
<div class="f6 f5-l lh-copy nested-copy-line-height">
|
||||
{{ .Summary }}
|
||||
</div>
|
||||
{{/* TODO: add author
|
||||
<p class="f6 lh-copy mv0">By {{ .Author }}</p> */}}
|
||||
</div>
|
||||
</div>
|
||||
</a>
|
||||
</article>
|
||||
15
themes/gs/layouts/post/summary.html
Normal file
15
themes/gs/layouts/post/summary.html
Normal file
|
|
@ -0,0 +1,15 @@
|
|||
<div class="mb3 pa4 mid-gray overflow-hidden">
|
||||
{{ if .Date }}
|
||||
<div class="f6">
|
||||
{{ .Date.Format "January 2, 2006" }}
|
||||
</div>
|
||||
{{ end }}
|
||||
<h1 class="f3 near-black">
|
||||
<a href="{{ .Permalink }}" class="link black dim">
|
||||
{{ .Title }}
|
||||
</a>
|
||||
</h1>
|
||||
<div class="nested-links f5 lh-copy nested-copy-line-height">
|
||||
{{ .Summary }}
|
||||
</div>
|
||||
</div>
|
||||
8
themes/gs/layouts/robots.txt
Normal file
8
themes/gs/layouts/robots.txt
Normal file
|
|
@ -0,0 +1,8 @@
|
|||
User-agent: *
|
||||
# robotstxt.org - if ENV production variable is false robots will be disallowed.
|
||||
{{ if eq (getenv "HUGO_ENV") "production" | or (eq .Site.Params.env "production") }}
|
||||
Allow: /
|
||||
Sitemap: {{.Site.BaseURL}}/sitemap.xml
|
||||
{{ else }}
|
||||
Disallow: /
|
||||
{{ end }}
|
||||
376
themes/gs/static/css/styles.css
Normal file
376
themes/gs/static/css/styles.css
Normal file
|
|
@ -0,0 +1,376 @@
|
|||
/*
|
||||
* Based on Skeleton V2.0.4
|
||||
*
|
||||
*
|
||||
* Skeleton
|
||||
* Copyright 2014, Dave Gamache
|
||||
* www.getskeleton.com
|
||||
* Free to use under the MIT license.
|
||||
* http://www.opensource.org/licenses/mit-license.php
|
||||
* 12/29/2014
|
||||
*/
|
||||
|
||||
/**
|
||||
* Language highlight colours. Should be or match the language/technology's
|
||||
* branding guidelines.
|
||||
*/
|
||||
:root {
|
||||
--background-colour: #fff;
|
||||
--text-colour: #222;
|
||||
--php: rgb(136, 146, 191);
|
||||
--javascript: #83CD29;
|
||||
--go: #00ADD8;
|
||||
--flutter: #02569B;
|
||||
--clojure: #62B132;
|
||||
--rust: #DEA584;
|
||||
--python: #4584B6;
|
||||
}
|
||||
|
||||
.pill {
|
||||
border: 1px solid var(--text-colour);
|
||||
font-size: 55%;
|
||||
padding: 0 10px;
|
||||
vertical-align: middle;
|
||||
border-radius: 5px;
|
||||
font-weight: bold;
|
||||
background-color: var(--text-colour);
|
||||
color: var(--background-colour);
|
||||
}
|
||||
|
||||
.php {
|
||||
background-color: var(--php);
|
||||
border-color: var(--php);
|
||||
color: var(--background-colour);
|
||||
}
|
||||
.javascript {
|
||||
background-color: var(--javascript);
|
||||
border-color: var(--javascript);
|
||||
color: var(--background-colour);
|
||||
}
|
||||
.go {
|
||||
background-color: var(--go);
|
||||
border-color: var(--go);
|
||||
color: var(--background-colour);
|
||||
}
|
||||
.flutter {
|
||||
background-color: var(--flutter);
|
||||
border-color: var(--flutter);
|
||||
color: var(--background-colour);
|
||||
}
|
||||
.clojure {
|
||||
background-color: var(--clojure);
|
||||
border-color: var(--clojure);
|
||||
color: var(--background-colour);
|
||||
}
|
||||
.rust {
|
||||
background-color: var(--rust);
|
||||
border-color: var(--rust);
|
||||
color: var(--background-colour);
|
||||
}
|
||||
.python {
|
||||
background-color: var(--python);
|
||||
border-color: var(--python);
|
||||
color: var(--background-colour);
|
||||
}
|
||||
|
||||
.pagination {
|
||||
width: 50%;
|
||||
margin: 0 auto;
|
||||
}
|
||||
|
||||
.pagination > ul {
|
||||
list-style: none;
|
||||
display: flex;
|
||||
justify-content: space-between;
|
||||
}
|
||||
|
||||
/* Base Styles
|
||||
–––––––––––––––––––––––––––––––––––––––––––––––––– */
|
||||
/* NOTE
|
||||
html is set to 62.5% so that all the REM measurements throughout Skeleton
|
||||
are based on 10px sizing. So basically 1.5rem = 15px :) */
|
||||
* {
|
||||
box-sizing: border-box;
|
||||
text-rendering: optimizeLegibility;
|
||||
-webkit-font-smoothing: antialiased;
|
||||
-moz-osx-font-smoothing: grayscale;
|
||||
font-kerning: auto;
|
||||
}
|
||||
|
||||
html {
|
||||
font-size: 62.5%;
|
||||
-webkit-text-size-adjust: 100%;
|
||||
}
|
||||
body {
|
||||
font-size: 1.6em; /* currently ems cause chrome bug misinterpreting rems on body element */
|
||||
line-height: 1.6;
|
||||
font-weight: 400;
|
||||
font-family: -apple-system, BlinkMacSystemFont, "Segoe UI", Roboto, Oxygen-Sans, Ubuntu, Cantarell, "Helvetica Neue", sans-serif;
|
||||
color: var(--text-colour);
|
||||
background-color: var(--background-colour);
|
||||
margin: 20px 0;
|
||||
}
|
||||
|
||||
@media (prefers-color-scheme: dark) {
|
||||
:root {
|
||||
--background-colour: #202225;
|
||||
--text-colour: #dcddde;
|
||||
--flutter: #0175C2;
|
||||
--python: #FFDE57;
|
||||
}
|
||||
.pill {
|
||||
border: 1px solid var(--text-colour);
|
||||
background-color: var(--background-colour);
|
||||
color: var(--text-colour);
|
||||
}
|
||||
.php {
|
||||
background-color: var(--background-colour);
|
||||
border-color: var(--php);
|
||||
color: var(--php);
|
||||
}
|
||||
.javascript {
|
||||
background-color: var(--background-colour);
|
||||
border-color: var(--javascript);
|
||||
color: var(--javascript);
|
||||
}
|
||||
.go {
|
||||
background-color: var(--background-colour);
|
||||
border-color: var(--go);
|
||||
color: var(--go);
|
||||
}
|
||||
.flutter {
|
||||
background-color: var(--background-colour);
|
||||
border-color: var(--go);
|
||||
color: var(--go);
|
||||
}
|
||||
.clojure {
|
||||
background-color: var(--background-colour);
|
||||
border-color: var(--clojure);
|
||||
color: var(--clojure);
|
||||
}
|
||||
.rust {
|
||||
background-color: var(--background-colour);
|
||||
border-color: var(--rust);
|
||||
color: var(--rust);
|
||||
}
|
||||
.python {
|
||||
background-color: var(--background-colour);
|
||||
border-color: var(--python);
|
||||
color: var(--python);
|
||||
}
|
||||
}
|
||||
|
||||
/* Grid
|
||||
–––––––––––––––––––––––––––––––––––––––––––––––––– */
|
||||
.container {
|
||||
position: relative;
|
||||
width: 100%;
|
||||
max-width: 960px;
|
||||
margin: 0 auto;
|
||||
padding: 0 20px;
|
||||
box-sizing: border-box; }
|
||||
.column,
|
||||
.columns {
|
||||
width: 100%;
|
||||
float: left;
|
||||
box-sizing: border-box; }
|
||||
|
||||
/* For devices larger than 400px */
|
||||
@media (min-width: 400px) {
|
||||
.container {
|
||||
width: 85%;
|
||||
padding: 0;
|
||||
}
|
||||
}
|
||||
|
||||
/* For devices larger than 550px */
|
||||
@media (min-width: 550px) {
|
||||
.container {
|
||||
width: 80%;
|
||||
}
|
||||
.column,
|
||||
.columns {
|
||||
margin-left: 4%;
|
||||
}
|
||||
.column:first-child,
|
||||
.columns:first-child {
|
||||
margin-left: 0;
|
||||
}
|
||||
|
||||
.one.column,
|
||||
.one.columns { width: 4.66666666667%; }
|
||||
.two.columns { width: 13.3333333333%; }
|
||||
.three.columns { width: 22%; }
|
||||
.four.columns { width: 30.6666666667%; }
|
||||
.five.columns { width: 39.3333333333%; }
|
||||
.six.columns { width: 48%; }
|
||||
.seven.columns { width: 56.6666666667%; }
|
||||
.eight.columns { width: 65.3333333333%; }
|
||||
.nine.columns { width: 74.0%; }
|
||||
.ten.columns { width: 82.6666666667%; }
|
||||
.eleven.columns { width: 91.3333333333%; }
|
||||
.twelve.columns { width: 100%; margin-left: 0; }
|
||||
|
||||
.one-third.column { width: 30.6666666667%; }
|
||||
.two-thirds.column { width: 65.3333333333%; }
|
||||
|
||||
.one-half.column { width: 48%; }
|
||||
}
|
||||
|
||||
/* Typography
|
||||
–––––––––––––––––––––––––––––––––––––––––––––––––– */
|
||||
h1, h2, h3, h4, h5, h6 {
|
||||
margin-top: 0;
|
||||
margin-bottom: 2rem;
|
||||
font-weight: 300; }
|
||||
h1 { font-size: 4.0rem; line-height: 1.2; font-weight: 500; }
|
||||
h2 { font-size: 3.6rem; line-height: 1.25; }
|
||||
h3 { font-size: 3.0rem; line-height: 1.3; font-weight: 500; }
|
||||
h4 { font-size: 2.4rem; line-height: 1.35; }
|
||||
h5 { font-size: 1.8rem; line-height: 1.5; }
|
||||
h6 { font-size: 1.5rem; line-height: 1.6; }
|
||||
|
||||
.project h4, .experiment h4 {
|
||||
margin-bottom: 0.05rem;
|
||||
}
|
||||
|
||||
/* Larger than phablet */
|
||||
@media (min-width: 550px) {
|
||||
h1 { font-size: 5.0rem; }
|
||||
h2 { font-size: 4.2rem; }
|
||||
h3 { font-size: 3.6rem; }
|
||||
h4 { font-size: 3.0rem; }
|
||||
h5 { font-size: 2.4rem; }
|
||||
h6 { font-size: 1.5rem; }
|
||||
}
|
||||
|
||||
p {
|
||||
margin-top: 0;
|
||||
}
|
||||
|
||||
|
||||
/* Links
|
||||
–––––––––––––––––––––––––––––––––––––––––––––––––– */
|
||||
a {
|
||||
color: #1EAEDB;
|
||||
}
|
||||
a:hover {
|
||||
color: #0FA0CE;
|
||||
}
|
||||
|
||||
|
||||
/* Buttons
|
||||
–––––––––––––––––––––––––––––––––––––––––––––––––– */
|
||||
.button,
|
||||
button,
|
||||
input[type="submit"],
|
||||
input[type="reset"],
|
||||
input[type="button"] {
|
||||
display: inline-block;
|
||||
height: 38px;
|
||||
padding: 0 30px;
|
||||
color: #555;
|
||||
text-align: center;
|
||||
font-size: 11px;
|
||||
font-weight: 600;
|
||||
line-height: 38px;
|
||||
text-transform: uppercase;
|
||||
text-decoration: none;
|
||||
white-space: nowrap;
|
||||
background-color: transparent;
|
||||
border-radius: 4px;
|
||||
border: 1px solid #bbb;
|
||||
cursor: pointer;
|
||||
box-sizing: border-box; }
|
||||
.button:hover,
|
||||
button:hover,
|
||||
input[type="submit"]:hover,
|
||||
input[type="reset"]:hover,
|
||||
input[type="button"]:hover,
|
||||
.button:focus,
|
||||
button:focus,
|
||||
input[type="submit"]:focus,
|
||||
input[type="reset"]:focus,
|
||||
input[type="button"]:focus {
|
||||
color: #333;
|
||||
border-color: #888;
|
||||
outline: 0; }
|
||||
.button.button-primary,
|
||||
button.button-primary,
|
||||
input[type="submit"].button-primary,
|
||||
input[type="reset"].button-primary,
|
||||
input[type="button"].button-primary {
|
||||
color: #FFF;
|
||||
background-color: #33C3F0;
|
||||
border-color: #33C3F0; }
|
||||
.button.button-primary:hover,
|
||||
button.button-primary:hover,
|
||||
input[type="submit"].button-primary:hover,
|
||||
input[type="reset"].button-primary:hover,
|
||||
input[type="button"].button-primary:hover,
|
||||
.button.button-primary:focus,
|
||||
button.button-primary:focus,
|
||||
input[type="submit"].button-primary:focus,
|
||||
input[type="reset"].button-primary:focus,
|
||||
input[type="button"].button-primary:focus {
|
||||
color: #FFF;
|
||||
background-color: #1EAEDB;
|
||||
border-color: #1EAEDB; }
|
||||
|
||||
/* Spacing
|
||||
–––––––––––––––––––––––––––––––––––––––––––––––––– */
|
||||
button,
|
||||
.button {
|
||||
margin-bottom: 1rem; }
|
||||
input,
|
||||
textarea,
|
||||
select,
|
||||
fieldset {
|
||||
margin-bottom: 1.5rem; }
|
||||
pre,
|
||||
blockquote,
|
||||
dl,
|
||||
figure,
|
||||
table,
|
||||
p,
|
||||
ul,
|
||||
ol,
|
||||
form {
|
||||
margin-bottom: 2.5rem; }
|
||||
|
||||
|
||||
/* Utilities
|
||||
–––––––––––––––––––––––––––––––––––––––––––––––––– */
|
||||
.u-full-width {
|
||||
width: 100%;
|
||||
box-sizing: border-box; }
|
||||
.u-max-full-width {
|
||||
max-width: 100%;
|
||||
box-sizing: border-box; }
|
||||
.u-pull-right {
|
||||
float: right; }
|
||||
.u-pull-left {
|
||||
float: left; }
|
||||
|
||||
|
||||
/* Misc
|
||||
–––––––––––––––––––––––––––––––––––––––––––––––––– */
|
||||
hr {
|
||||
margin-top: 3rem;
|
||||
margin-bottom: 3.5rem;
|
||||
border-width: 0;
|
||||
border-top: 1px solid var(--text-colour);
|
||||
}
|
||||
|
||||
|
||||
/* Clearing
|
||||
–––––––––––––––––––––––––––––––––––––––––––––––––– */
|
||||
|
||||
/* Self Clearing Goodness */
|
||||
.container:after,
|
||||
.row:after,
|
||||
.u-cf {
|
||||
content: "";
|
||||
display: table;
|
||||
clear: both;
|
||||
}
|
||||
6
themes/gs/theme.toml
Normal file
6
themes/gs/theme.toml
Normal file
|
|
@ -0,0 +1,6 @@
|
|||
# Roughly forked from https://themes.gohugo.io/themes/gohugo-theme-ananke/ used
|
||||
# for reference.
|
||||
|
||||
name = "blog.gabrielsimmer.com Theme"
|
||||
description = "Theme for blog.gabrielsimmer.com"
|
||||
homepage = "https://blog.gabrielsimmer.com"
|
||||
Loading…
Reference in a new issue